本文是CSK与KCF算法推导的第二篇,主要介绍标量对向量求导、核函数、岭回归问题求解等内容。
向量求导
很多论文里的数学推导都离不开对向量求导。对向量求导的本质也是对一个个分量求导,用向量写起来就非常紧凑美观。向量分为行向量和列向量,习惯上我们都是把变量写成列向量,所以大多数情况都是对列向量求导。有些书里提出了“分子布局”、“分母布局”的概念,帮助阐述如何对向量求导,但我怕比较繁琐就不在这里介绍了。
标量对向量求导
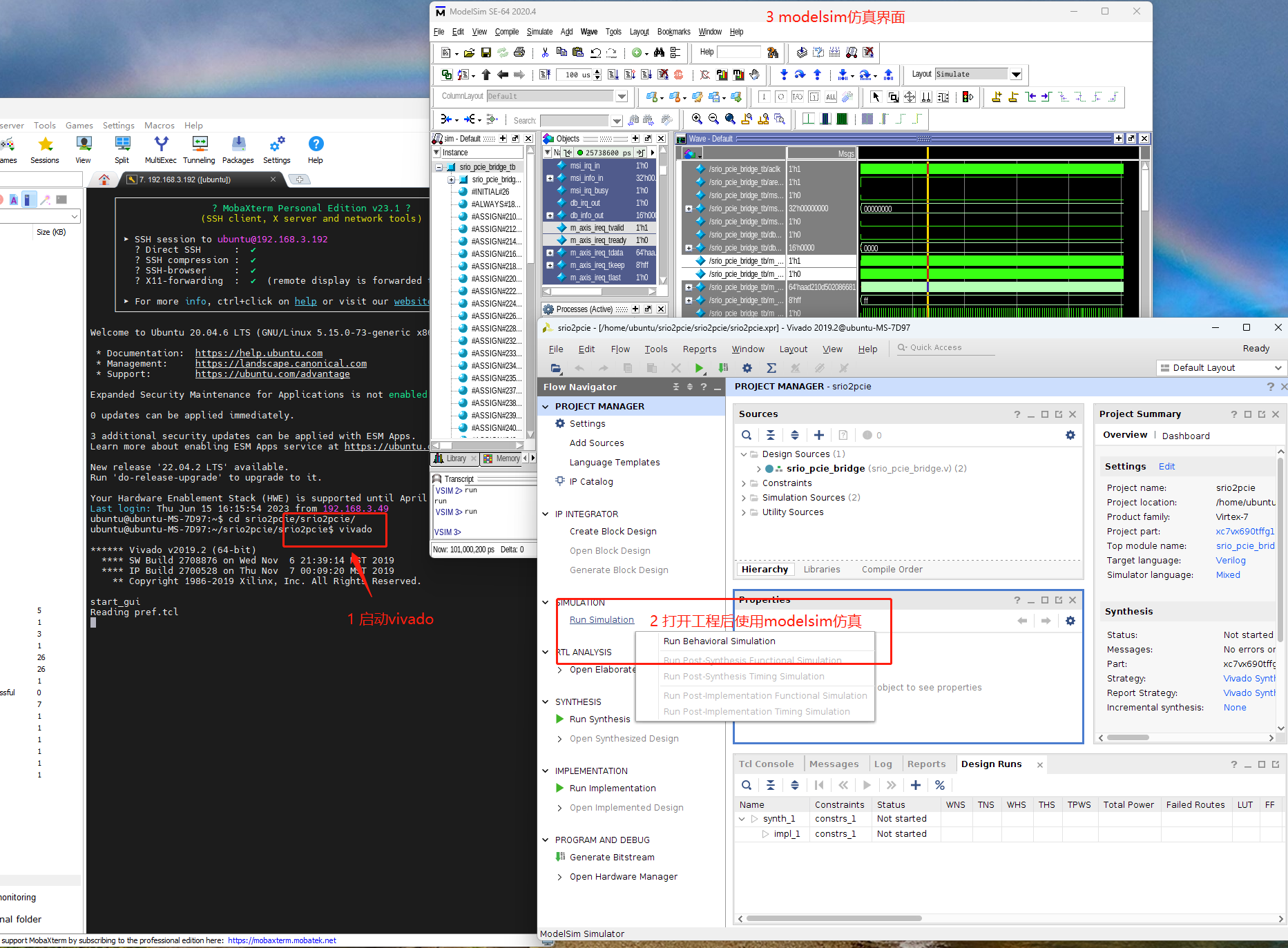
两个向量的内积可以得到一个标量,这个标量对向量求导实际上是对向量的每个分量分别求导。设q={q1,q2,q3⋯qn}T,x={x1,x2,x3,⋯xn}T,q和x都是n维的列向量。把q和x的内积写成多项式的形式:
y=<q,x>=qTx=xTq=q1x1+q2x2+q3x3+⋯+qnxn
然后分别对x的每个分量求导,结果也可以写成列向量。
∂x∂y=∂x∂qTx=∂x∂xTq=⎣⎡x1∂(q1x1+q2x2+q3x3+⋯+qnxn)x2∂(q1x1+q2x2+q3x3+⋯+qnxn)x3∂(q1x1+q2x2+q3x3+⋯+qnxn)⋮xn∂(q1x1+q2x2+q3x3+⋯+qnxn)⎦⎤=⎣⎡q1q2q3⋮qn⎦⎤=q
在这里我们可以写一下全微分的形式,便于后面的理解:
dy=∂x1∂ydx1+∂x2∂ydx2+∂x3∂ydx3+⋯+∂xn∂ydxn=(∂x∂y)Tdx
由偏导数组合而成的向量q是这个函数y的梯度向量。梯度向量q和自变量的微分量dx的内积就是y的微分量。为了统一形式,我们不如就约定,梯度向量都写成列向量。
向量对向量求导
从标量对向量求导推广到向量对向量求导就很简单了。从上面的一次内积推广到多次内积,结果以列向量表示。
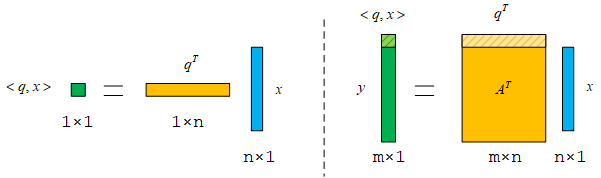
这时候列向量y对列向量x求偏导的结果应该为A,这样能够和前面的结论保持一致。
∂x∂y=∂x∂ATx=A
矩阵A具体应该怎么求呢?应该y的分量横着写,然后竖着写每个分量对x的偏导数,这样子A中每一列都是一个梯度向量。

海森(Hessian)矩阵
掌握了上面的求导方式之后,就可以求海森矩阵了。海森矩阵是多元函数的二阶偏导数构成的方阵。这里引入一个梯度算符“∇”,求多元函数f(x)的梯度向量可以用“∇xf”表示,f(x)的海森矩阵就是“∇x2f”。
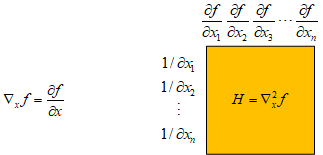
求导法则
上面介绍了两个重要的公式∂qTx/∂x=∂xTq/∂x=q和∂ATx/∂x=A,在很多要求梯度的情况下都可以用这个这两个公式,再结合线性求导法则,乘法求导法则,链式求导法则,基本上就不会有大问题了。
∂x∂(c1f(x)+c2g(x))=c1∂x∂f(x)+c2∂x∂g(x)
∂x∂(f(x)g(x))=∂x∂f(x)g(x)+f(x)∂x∂g(x)
这两条法则分别是线性求导法则和乘法求导法则,这个在标量对标量求导时适用,在对向量求导时也同样适用,大家肯定都比较熟悉了。但是链式求导法则和我们以前的经验有一点不一样,以前不需要注意左右顺序,但这里需要。
前面我们写过一个全微分式子,就是dy=(∂y/∂x)Tdx。从这里能够看到,要求梯度向量∂y/∂x还可以通过先写全微分表达式,然后再对微分变量dx前面的向量/矩阵转置来得到。我们可以用这个结论来推导链式求导法则。设y=f(g(x)),求∂y/∂x,先写我们已知的结论:
dy=(∂x∂y)Tdx
设u=g(x),写出全微分关系式:
dy=(∂u∂y)Tdudu=(∂x∂u)Tdx→dy=(∂u∂y)T(∂x∂u)Tdx
上面的式子的含义就是x的微小变化与u对x的梯度向量的内积可以得到u的微小变化;u的微小变化与y对u的梯度向量的内积可以得到y的微小变化。对比上面两个式子可以得出:
∂x∂y=((∂u∂y)T(∂x∂u)T)T=∂x∂u∂u∂y
如果函数嵌套的层数更多,结果也是类似的,函数从里往外依次求偏导,得到的结果依次从左往右相乘。如果不注意左右顺序,矩阵维度就无法对应。
2022年3月27日补充
标量对矩阵求导
类似标量对向量求导,求导结果与自变量是相同的维度。
dy=<∂x∂y,dx>=(∂x∂y)Tdx
标量对矩阵求导也应当是类似的形式。比如有一个m×n的矩阵W和一个标量s,它们之间满足这样的关系:
ds=<∂W∂s,dW>=tr((∂W∂s)TdW)
dW和∂s/∂W都是m×n的矩阵,我们用迹函数来表示矩阵内积。迹函数有一个特殊的性质:
tr(ABC)=tr(BCA)=tr(CAB)
三个矩阵A、B、C相乘得到一个方阵,它们循环移位后再相乘,不会改变结果的迹。之所以要求循环移位,是要让矩阵之间相乘的维度能够对应上。具体证明过程……我也不清楚,但是举几个简单的例子试一下会发现它确实是成立的。
向量对矩阵求导
如果顺着上面的思路来,向量对矩阵求导,就是向量中的每个分量对矩阵求导再组合在一起,这将是一个三维的张量。但有时候我们又会发现,比如s=Wx,向量s中的分量并不是和矩阵W中的每个分量都有关的,如果按照前面的思路来,得到的将会是一个稀疏的结果。更直观的感觉可能是s对W求偏导应该得到一个向量,因为s是由矩阵W和向量x相乘得到的。
遇到这种情况我觉得还是得具体问题具体分析,一般写成微分的形式肯定没问题,然后可以代入其他地方进行计算。
ds=(dW)x
岭回归
机器学习中的“回归”是相对于“分类”来说的,回归用于预测连续值,这里有点类似于数学上的拟合。
设有一组样本X和样本对应的标签y。X中每一行是一个样本,每个样本在标签y中有一个对应的结果。我们的目的是找到样本X和标签y的一组线性关系,使样本xi经过线性运算的结果能尽可能接近标签值yi。
ω1xi1+ω2xi2+ω3xi3+⋯+ωnxin→yi
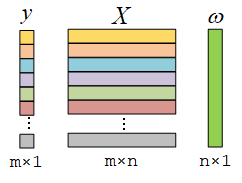
所以问题实际上是结合已有的数据求最优的系数ω,最常见的做法是最小二乘法,最小二乘法的目的是使计算结果和标签的平方误差最小。而岭回归是在最小二乘法基础上引入了正则项,防止过拟合,提高了计算的稳定性。
写出目标函数L,优化ω来令目标函数最小化。
ωminL=∣∣y−Xω∣∣2+λ∣∣ω∣∣2
类似一元二次函数,令梯度向量为零向量可以取到L的最小值。
∂ω∂L=∂ω∂((y−Xω)T(y−Xω)+λωTω)=−XT2(y−Xω)+2λω=0
上面的求导过程用了链式求导法则、乘法求导法则和线性求导法则。整理之后可以得到:
ω=(XTX+λI)−1XTy
相比于最小二乘法,岭回归的结果多了λI,就像是一条山“岭”加在方阵XTX上,所以起名叫“岭回归”。原先最小二乘法计算过程中有可能XTX不是满秩,无法求逆。现在加上了λI就一定能求逆了,所以提高了计算的稳定性。
这里看上去只能求样本和标签的线性关系,但如果xi的分量中用的是多项式、指数函数、三角函数等,它也能够用来求解。这时候是将结果用一些多项式或者初等函数的线性组合来描述,不同的拟合方式取决于构建的模型。
表示定理(Representer Theorem)
考虑一个线性回归问题:
ωmini∑mL(ωTxi,yi)+λ∣∣ω∣∣2
表示定理所描述的问题相比于岭回归更加一般化,这里的误差函数也是任意的,而岭回归用的是最小平方误差。
ω和x是相同维度n的向量,总共有m个样本,设ω=ω∥+ω⊥,其中ω∥存在于所有样本xi张成的子空间,就是说ω∥可以用所有样本来线性表示;而ω⊥则是和每个样本都垂直,ω⊥和每个样本的内积都是0。
ω∥=i∑mαixiω⊥Txi=0
这里的α存在于对偶空间,ω存在于源空间。
这样的分解一定是合理的,ω∥存在于样本的生成子空间,而ω⊥存在于这个生成子空间的直和补子空间。它们俩的和可以用来表示全空间中的任意向量。把它们代入原问题中:
ωmini∑mL(ω∥Txi+ω⊥Txi,yi)+λ∣∣ω∥+ω⊥∣∣2=ωmini∑mL(ω∥Txi,yi)+λ∣∣ω∥∣∣2+λ∣∣ω⊥∣∣2
这个最小化问题,肯定希望∣∣ω⊥∣∣2越小越好;ω的最优解,肯定是在ω⊥=0的时候取到。所以ω=ω∥。有了这个先验条件之后,我们再回过头去看岭回归。
ω=(XTX+λI)−1XTy=XTα
这里用XTα表示样本的线性组合,因为X中的样本是一行一行放置的。
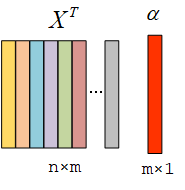
求解α:
(XTX+λI)XTα=XTyXT(XXT+λI)α=XTyα=(XXT+λI)−1y
再理一下我们求解的思路。前面的岭回归其实运算量比较大,涉及大量矩阵运算。现在在求ω之前引入一个中间变量α,让问题一下子简单了很多。
降低维度
XXT就是我在上一篇文章中提到的Gram矩阵,矩阵中的元素是样本两两之间的内积。求α是一个m维的运算,m是样本的个数。然后将α作为系数,对样本线性求和就能够得到ω。
这个在样本维度n非常大的时候非常有用,很多情况下我们会把样本映射到高维的特征空间,维度n往往会远大于样本个数m,这时候用这个方法求解就一下子把n维的问题降到m维!
将问题归结为内积运算
而且它也不需要显式地求出ω。比如当我们训练完成,然后输入新的一个样本z。
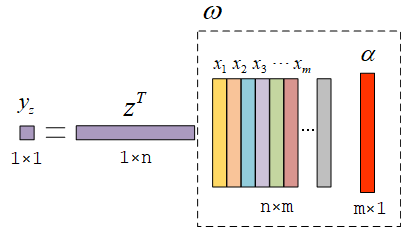
yz=zTXTα=[zTx1zTx2zTx3⋯zTxm]α
所以不管是训练的时候求α,还是输入新的样本进行推断,用到的都只是样本的内积,我们不用再去关心ω的具体形式。如果能有一个快速计算高维样本内积的方法就好了,这就用到了核函数。
核函数
核函数的引入实际上是通过一个φ(x)将低维的样本向量x映射到高维空间,这个高维空间一般称为特征空间。引入核函数以后,只是样本的维度增加了,对解的结构没有影响。核函数一般用κ(u,v)表示。
κ(u,v)=φ(u)Tφ(v)
它可以方便地计算φ(u)与φ(v)在高维空间的内积。而样本到了高维空间之后就有可能解决之前低维空间无法分类的问题。
所以在多了核函数以后,只是我们处理的样本维度变了,解的整体结构还是没有变,只要把前面求内积的地方换成核函数就好了。
带核函数的岭回归训练结果:
α=(K+λI)−1yKij=κ(xi,xj)
带核函数的岭回归前向推断:
yz=[κ(z,x1)κ(z,x2)κ(z,x3)⋯κ(z,xm)]α
P.S.关于对偶空间的解释
引用作者博士论文里的一张图,感觉解释得比较直观。