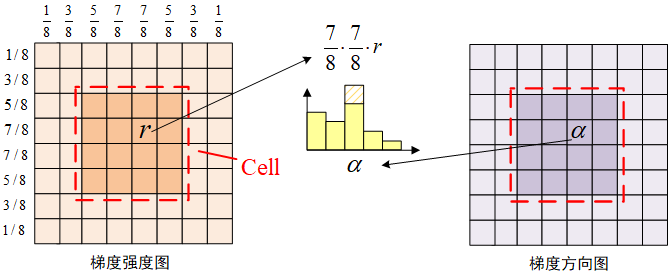
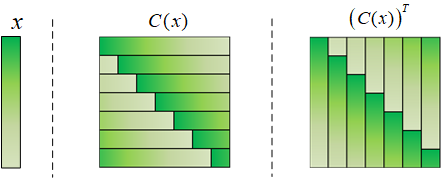
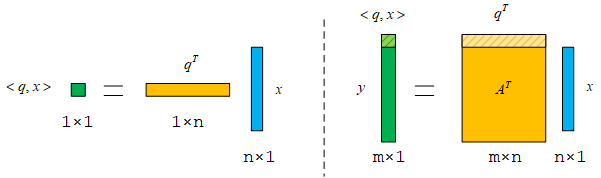本文是CSK与KCF算法推导的第四篇,主要介绍将前面推导采用的一维情况推广到二维。
KCF全文的推导都是建立在一维样本上的,但是实际使用却是用于二维的图像。那么它是怎样从一维推广到二维的呢?本文参照一维推导的思路给出二维的推导过程。
矩阵内积与矩阵的迹
二维的推导,需要定义一些新的运算。A和B都是m×n的矩阵,数学上有trace(ATB)表示矩阵对应位置元素相乘并求和的结果。参考向量内积,为了方便起见,定义两个矩阵的内积<A,B>,A和B都是m×n的矩阵。它们两个的内积就是矩阵中对应位置的数相乘再相加。
<A,B>:=trace(ATB)
矩阵阵列
用[⋅]表示矩阵阵列,矩阵阵列是一个四维的结构,就是矩阵里面嵌套矩阵。[⋅]uv表示矩阵阵列中的每个矩阵。
矩阵阵列和矩阵的乘法
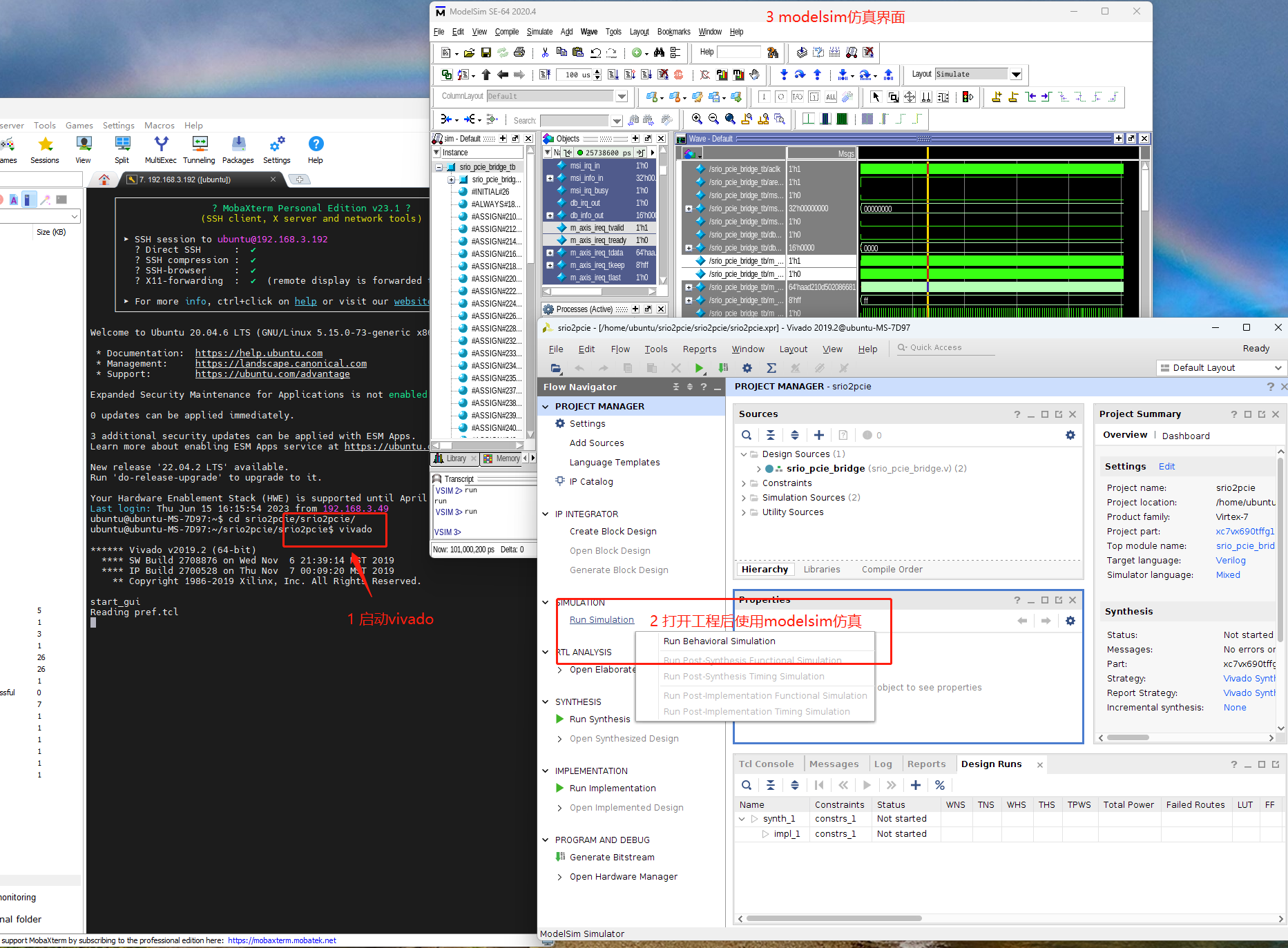
定义矩阵阵列和矩阵的乘法,用∘表示。如下图所示:
一个矩阵阵列[A]和一个矩阵B相乘,就是矩阵阵列[A]中的每个矩阵和B内积,然后结果放到对应的位置,得到一个新的矩阵。
[A]∘B=C C(x,y)=<[A]xy,B>
矩阵阵列和矩阵阵列的乘法
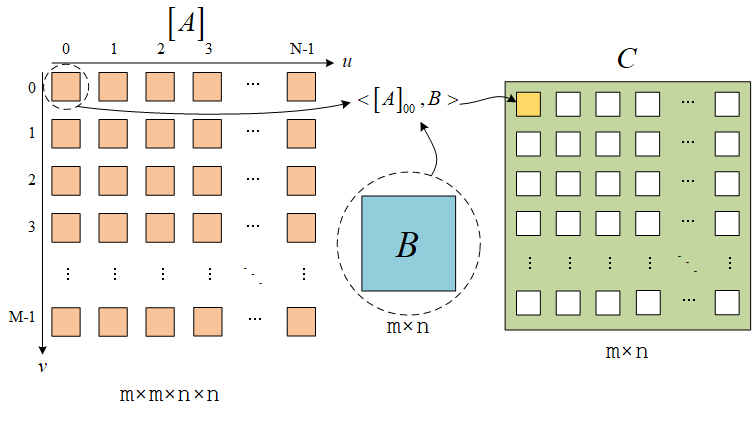
矩阵阵列和矩阵的乘法,类似于矩阵和列向量的乘法。自然,类似于矩阵和矩阵的乘法,我们也能有矩阵阵列和矩阵阵列的乘法。
矩阵阵列[A]依次和矩阵阵列[B]中的每个矩阵相乘,然后就能得到一个矩阵阵列[C]
[A]∘[B]uv=[C]uv
矩阵分裂
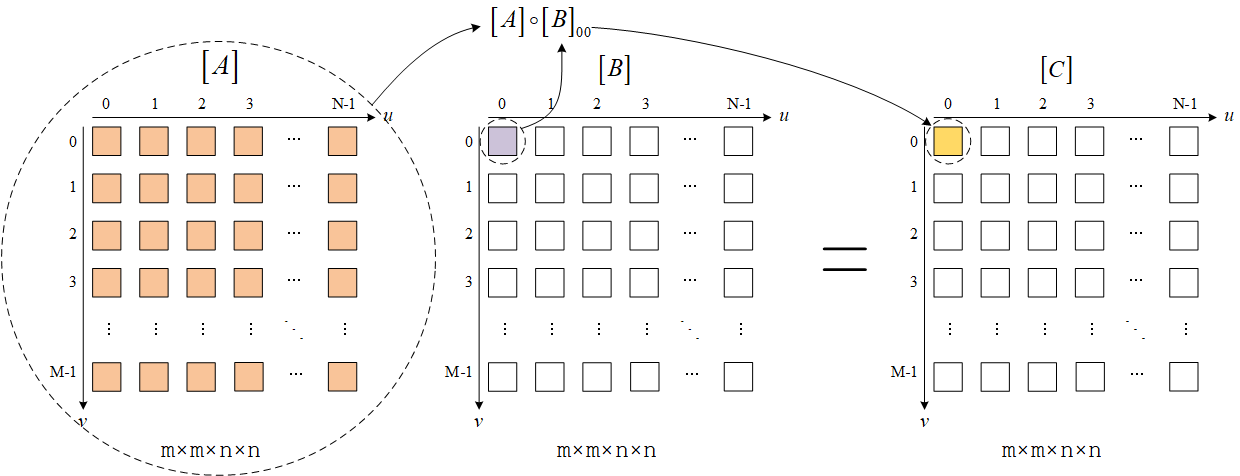
两个列向量的哈达玛积可以写成对角矩阵和列向量相乘的形式,两个矩阵的哈达玛积也可以写成一个矩阵阵列和矩阵相乘的形式。
定义split()函数,它可以将一个矩阵中的所有元素分散到矩阵阵列中的每个矩阵中去。类似于diag()的过程。
单位矩阵阵列
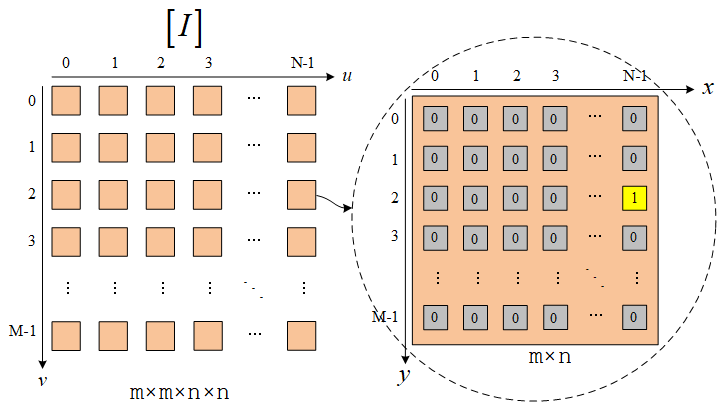
单位矩阵阵列指的是满足以下条件的矩阵阵列:
[I]uv(x,y)={1,x=u&y=v0,else
二维DFT的矩阵阵列表示
首先给出二维DFT运算的式子。有一个矩阵m×n的矩阵A(x,y),它的二维DFT结果为A^(u,v)。
A^(u,v)=y=0∑M−1x=0∑N−1A(x,y)WNuxWMvy
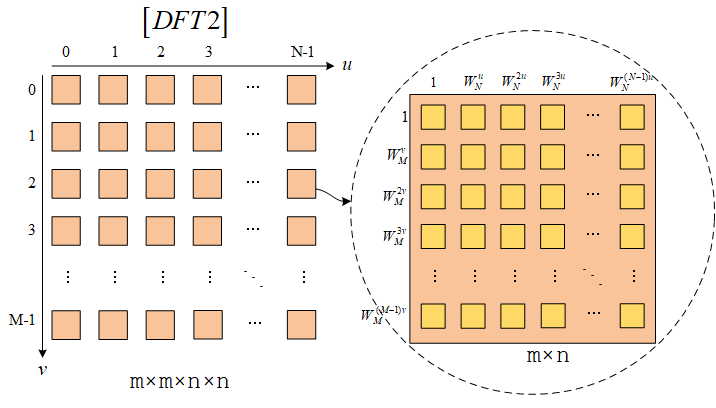
根据二维DFT的计算公式,我们可以直接画出二维DFT对应的矩阵阵列[DFT2]。上图中右边每个黄色方框内的值是对应的行列旋转因子相乘。类似一维情况下的推导,我们可以得出:
[DFT2]∘[DFT2]∗=MN[I]
(MN1[DFT2])∘(MN1[DFT2]∗)=[I]
二维相关运算
首先给出二维的相关运算:
f(x,y)=q=0∑M−1p=0∑N−1A(p,q)B(x+p,y+q)
F(u,v)=y=0∑M−1x=0∑N−1q=0∑M−1p=0∑N−1A(p,q)B(x+p,y+q)WNuxWMvy
F(u,v)=q=0∑M−1WM−vqp=0∑N−1A(p,q)WN−upx=0∑M−1WMv(y+q)y=0∑N−1B(x+p,y+q)WNu(x+p)=A^∗(u,v)B^(u,v)
二维相关运算也可以用二维DFT加速。
循环矩阵阵列
类似论文中提出的循环矩阵,这里我们定义循环矩阵阵列C(A),由m×n的矩阵A通过循环移位产生。
- 定义算符Pi,PiA表示矩阵A在沿着x正方向整体循环移位i个单位;
- 定义算符Qi,QiA表示矩阵A在沿着y正方向整体循环移位i个单位;
C(A)uv=PuQvA
这个图太难画了,但我觉得这应该不难理解,就和一维的向量循环移位构成矩阵类似,矩阵循环移位构成矩阵阵列。
C(A)∘B表示的就是相关运算。这里我没有用二维卷积是因为我没想到怎样在矩阵阵列里定义对应的转置运算
C(A)∘B=[IDFT2]∘(A^∗⊙B^)=[IDFT2]∘split(A^∗)([DFT2]∘B)
C(A)=[U∗]∘split(A^∗)∘[U]U=MN1[DFT2]
所以循环矩阵阵列也能够用DFT实现“分裂化”,即基础矩阵的二维DFT得到的结果分散到矩阵阵列的每个小矩阵中。正是因为能够做这样的特征分解,才有后面的element-wise的运算。
后面我推不下去了,二维的岭回归大概是每个样本都是一个矩阵,所有样本排列在一起构成矩阵阵列,样本的标签值是一个二维函数,要优化的目标ω也是一个二维的矩阵……
训练标签
左上角第一个点表示样本不发生循环移动,如果用二维高斯函数作为训练标签,而且一开始我们关心的目标在训练样本图像的正中央,那么二维标签的左上角才是峰值点,因为左上角对应的位移量为0。又因为是循环移位的结构,所以四个角落都是峰值。
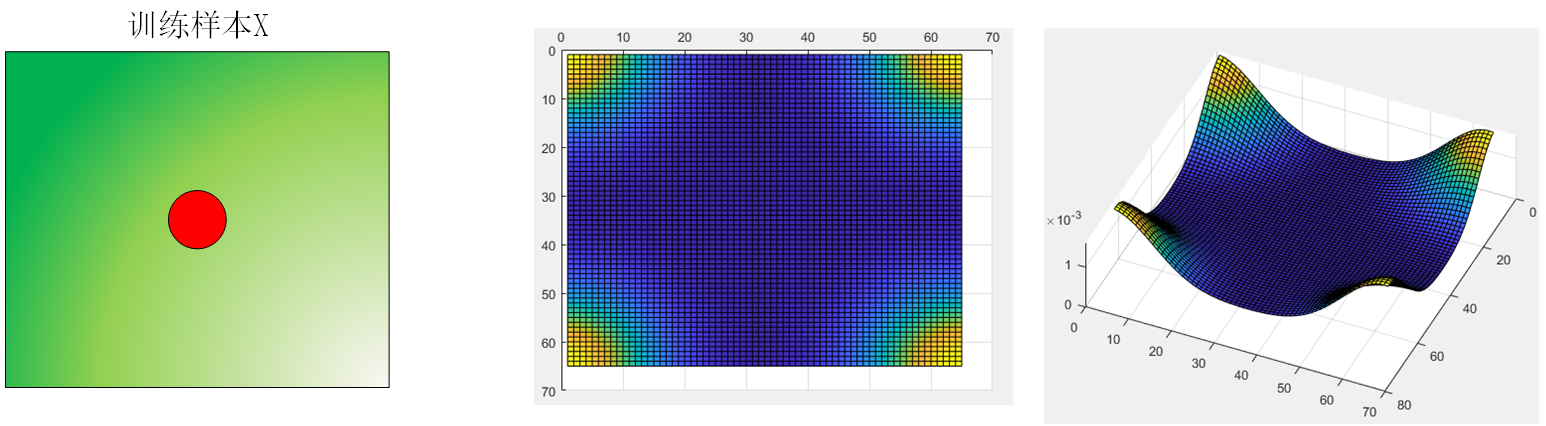
如果我们关心的目标在样本图像的左上角,那么这个训练样本需要向左和向下平移一半的图像大小才能将样本移动到正中央,那样对应的二维高斯标签就是峰值在中央的情况。但这样做是不合理的,因为如果目标在左上角,那么目标周围的上下文信息就是残缺的。在做DFT之前为了保持周期的连续性,防止频谱泄露,还需要在给样本加窗。那样在左上角的目标信息就会丢失。
所以如果目标是在训练样本的正中央的话,二维标签的峰值一定是在四个角落上。