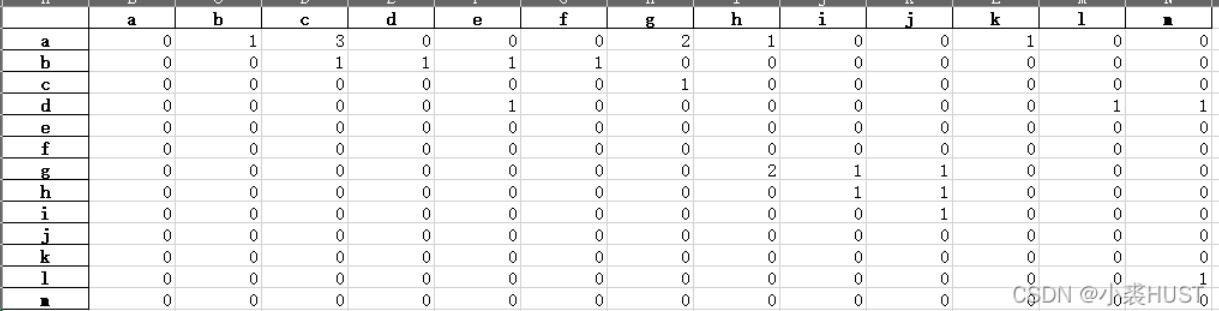
# 更新矩阵的行索引,逐行读取之后,如果matrix中没有这个键值就加一个新的 for name in names: if name in matrix: pass else: matrix[name] = {}
# 更新矩阵的列索引,并给矩阵赋初值0 namelist = list(matrix.keys()) for name in namelist: for subname in namelist: if subname in matrix[name]: pass else: matrix[name][subname] = 0
# 更新矩阵内容,把这一行中存在的合作关系在矩阵中的对应位置加一 for i inrange(len(names)-1): for j inrange(i+1, len(names), 1): matrix[names[i]][names[j]] = matrix[names[i]][names[j]] + 1 # 打印输出当前行数 print('line ' + str(cnt) + ' finished') cnt = cnt + 1
# 实际上这种合作关系是没有方向的,所以只需要一个上三角矩阵 # 下面就把矩阵中的相同含义的合作关系加在一起 # 比如a和b有合作,b和a也有合作,它们两个值就可以加起来给其中一个,然后把另一个赋0 namelist = list(matrix.keys()) for i inrange(len(namelist)-1): for j inrange(i+1, len(namelist), 1): matrix[namelist[i]][namelist[j]] = matrix[namelist[i]][namelist[j]] + matrix[namelist[j]][namelist[i]] matrix[namelist[j]][namelist[i]] = 0
# 把嵌套的字典转换成字典list的形式,便于后续转换成DataFrame格式 mlist = [] for i inrange(len(namelist)): mlist.append(matrix[namelist[i]])