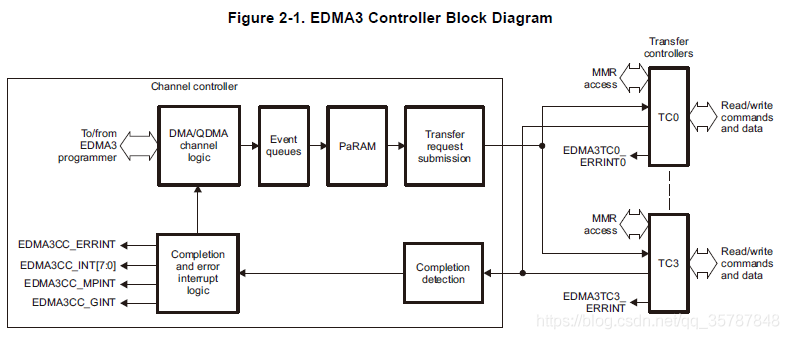
基于SRIO的FPGA与DSP间高速数据传输
引言
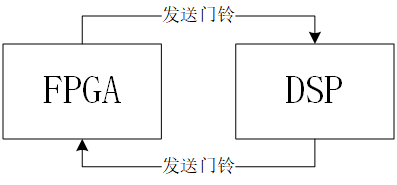
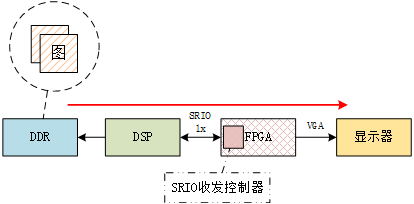
前段时间实现了DSP与FPGA之间的门铃通信,但SRIO不只是可以用来传门铃事务产生中断,它最大的优势在于能够实现嵌入式平台上的高速数据传输。我计划采用SWRITE事务包,从FPGA向DSP发送640×512×8bit图像数据,测试DSP端完成数据接收所需的时间。
参考资料:
- SPRU976E - TMS320C645x DSP Serial RapidIO (SRIO) User’s Guide
- SPRU732J - TMS320C64x/C64x+ DSP CPU and Instruction Set Reference Guide
FPGA发送数据至DSP
DSP端中断的产生在SPRU976E中有详细的说明,4.2节中指出,DSP在接收从外部送来的数据时,不管是Message还是Direct I/O的事务,外部的设备都需要通过门铃中断来告知DSP已经有数据传输完成。但是门铃事务和传数据的事务是独立的。如果发送端在发完数据后紧接着发门铃中断,有可能数据还未传输完成,DSP就已经开始响应门铃中断了。
为了避免这种情况的发生,发送端需要最后发送一个与前面发送的事务同样优先级的带响应的写(NWRITE_R),在接收到正确的响应后就能确保数据确实已经传输完成。再接着由发送端发起门铃中断,告知DSP传输完成。
测试过程示意图
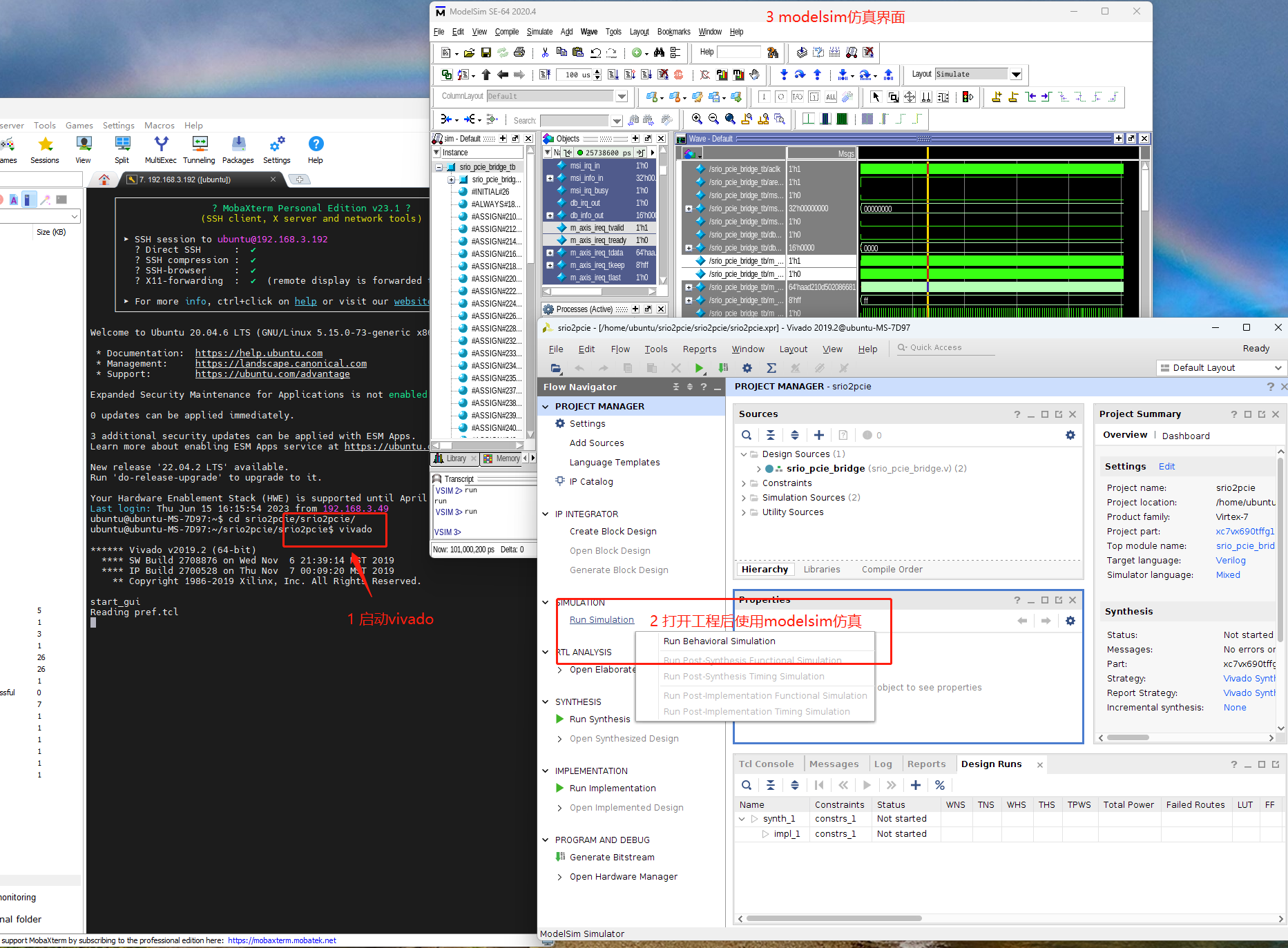
测试过程的示意图如上图所示,FPGA等待接收从DSP发过来的门铃信号,DB0和DB1分别指的是门铃的Info字段为“0”或者“1”的门铃事务,用于区分不同的工作模式。
DB0对应参照组,DSP端记录从发送门铃到接收门铃所用的时间。
DB1是测试组,FPGA在收到DB1后,先后依次发送1280包SWRITE事务,再发送NWAITE_R事务,收到响应后发送DB1。DSP记录总时间。
实际发送数据所用时间为:
DSP程序计时
DSP程序计时用的最多的感觉就是TSC(Time Stamp Counter Registers)寄存器。SPRU732J 的2.9.14对TSCL和TSCH两个寄存器有详细的介绍。这两个寄存器在初始化的时候默认是不启动的,可以往TSCL中写任意值来启动计时器,这个值不会被写入,因为这两个寄存器都是只读的,但是起到了启动计时器的功能。一旦计时器启动,就只能通过复位或者掉电来停止。
读当前的计时值也有讲究。先读TSCL,这时计时器实际的高32位的值也会写入TSCH,接着读TSCH,读到的就是准确的计时。两次读之间不要有中断,万一在中断中也有人去读TSC的值,那么之前的值就丢了。
一个寄存器32位,当前系统时钟1GHz,从0开始计数,只需要4.29s就能计满。而且有时候TSC的起点不是0,所以用的时间会更少,在计时的时候不能省略TSCH不读。
大小端问题
DSP端的SRIO用的是大端模式,而FPGA上实例化的Xilinx IP SRIO Gen2是小端模式。我感觉挺混乱的,实际测试发现,如果数据以字节为单位,那么每个字节中的bit顺序是对的;而每个字节的顺序是反的。
我利用状态机,控制ireq通道发送的数据,发送NWRITE_R事务包时,指定地址为0xE0050000,发送数据为64’hFEDCBA9876543210。
1 | …… |
结果如下图所示,最高地址的字节0xFE,到了最低的地址0xE0050000处,而0xFE本身还是0xFE,没有变成0x7F。
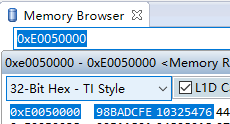
根据这一特点,在以后用SRIO的时候,需要在FPGA发送端对数据重新组织或者更改DSP的大小端模式。
测试结果
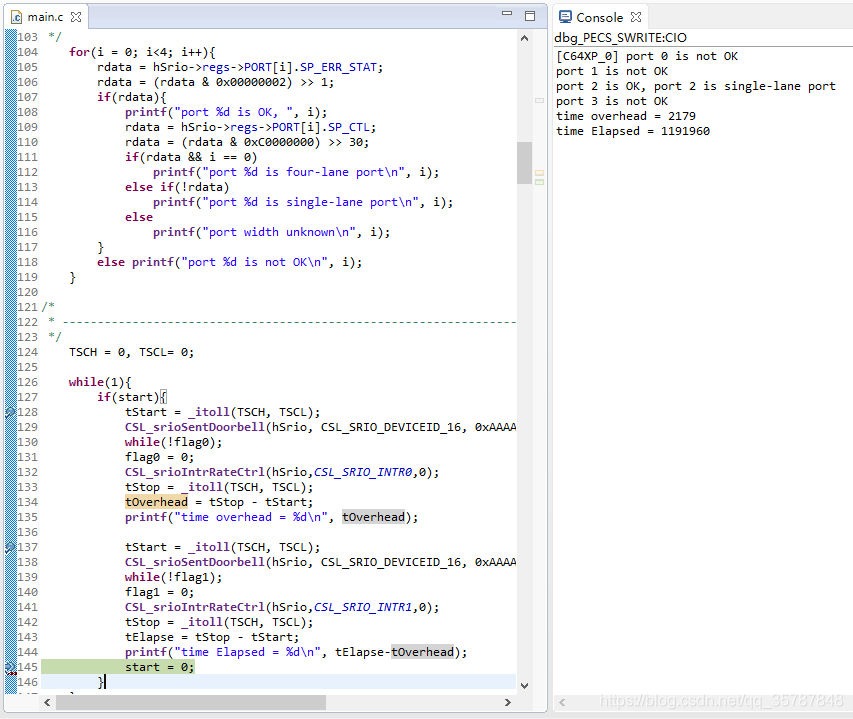
测试结果如上图所示,我们只用了port 2 上的一对链路,物理层的链路速率是3.125Gbps,DSP的主频是1GHz,因此这里的时间单位是ns。
对照组所用时间为2.179us,也就是发送并接收门铃的时间。测试组的结果已经减去了对照组中的额外时间开销,传输数据所用时间为1.191960ms。
有效数据带宽2.2Gbps,数据传输效率70.4%。
FPGA从DSP读数据
为了测试FPGA从DSP读数据的时间开销,同样设置有一组对照组和一组测试组。与前面的测试不同的是,这里FPGA完成的是读取数据的任务,在数据读取完成后向DSP发送中断。
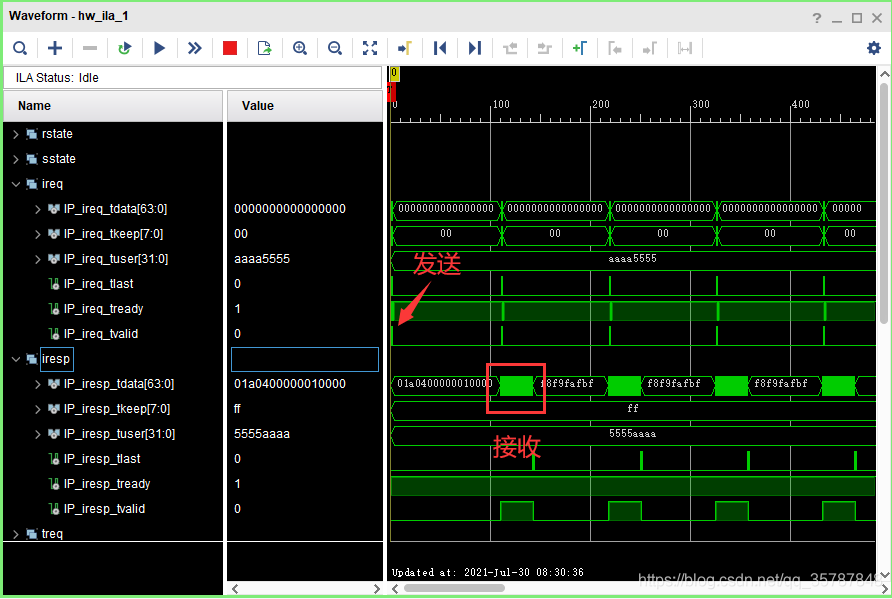
读数据并不是马上就能得到响应。FPGA每次在ireq端口发起NREAD事务之后,需要过一段时间才能在iresp端口读到数据。上图是相应的ILA波形,每次开始接收数据是,FPGA同时发起下一个NREAD事务。可以看到这里有大部分时间iresp通道都是空闲的状态,因此传输效率并没有发送图像数据时那么高。但这样做的优点是,整个过程不需要DSP干预,减轻了CPU的负担。
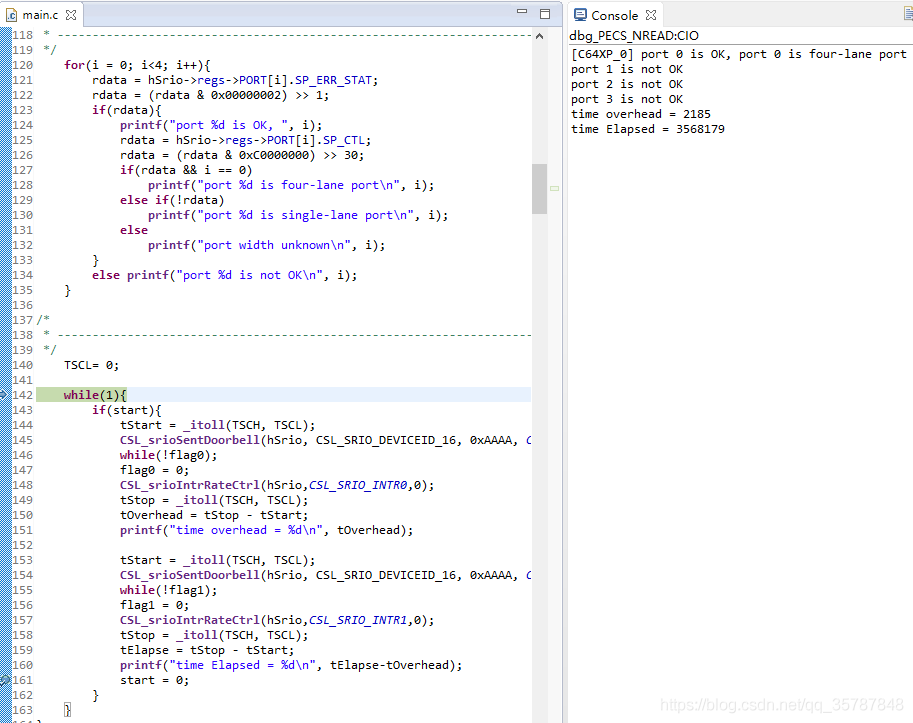
这里因为换了一块FPGA,所以也换了一个SRIO的端口,换到了端口0,不知道为什么它的通道工作模式指示的是4x的模式,实际上还是1x的链路。可以从上图看书,整个过程花的时间大概是3.568179ms。
有效数据带宽734.7Mbps,数据传输效率23.5%。接收数据的过程效率还可以进一步提高,但那样也会占用更多DSP的SRIO中的发送缓冲区的空间,更容易发生拥塞。