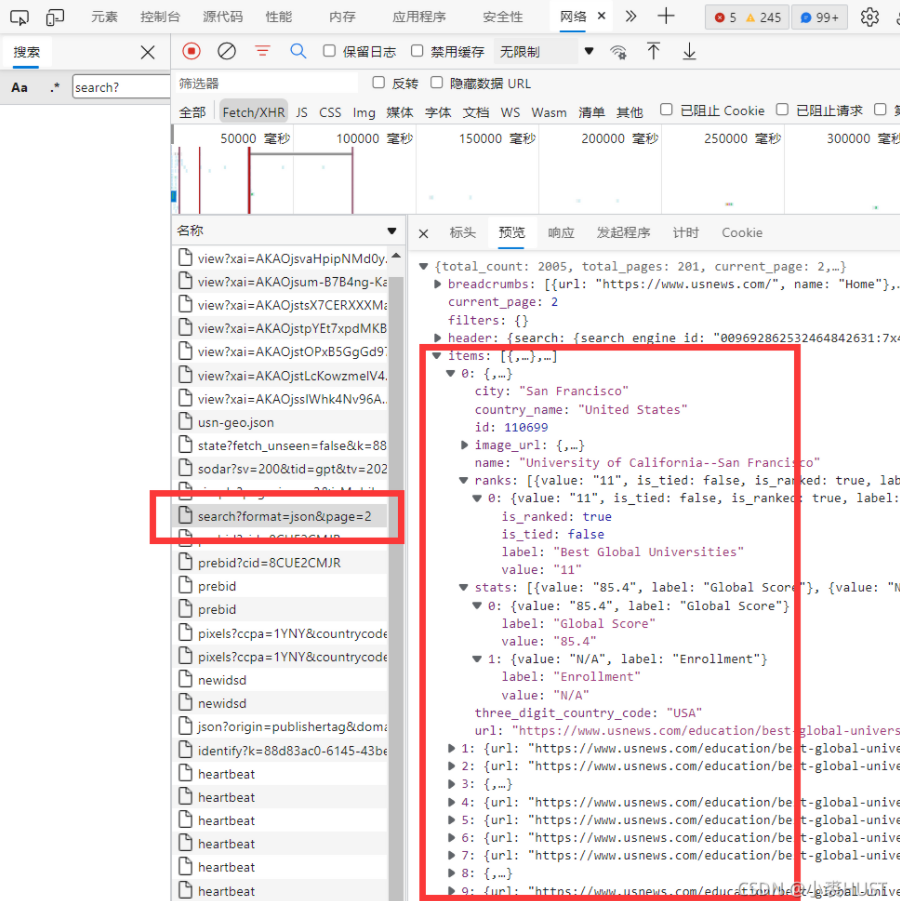
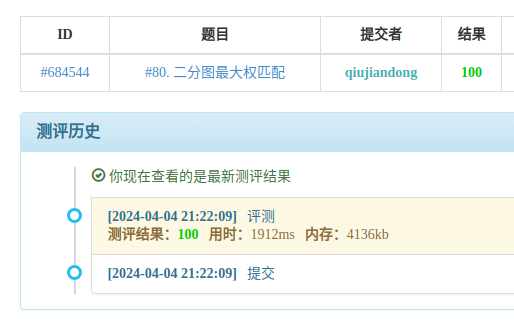
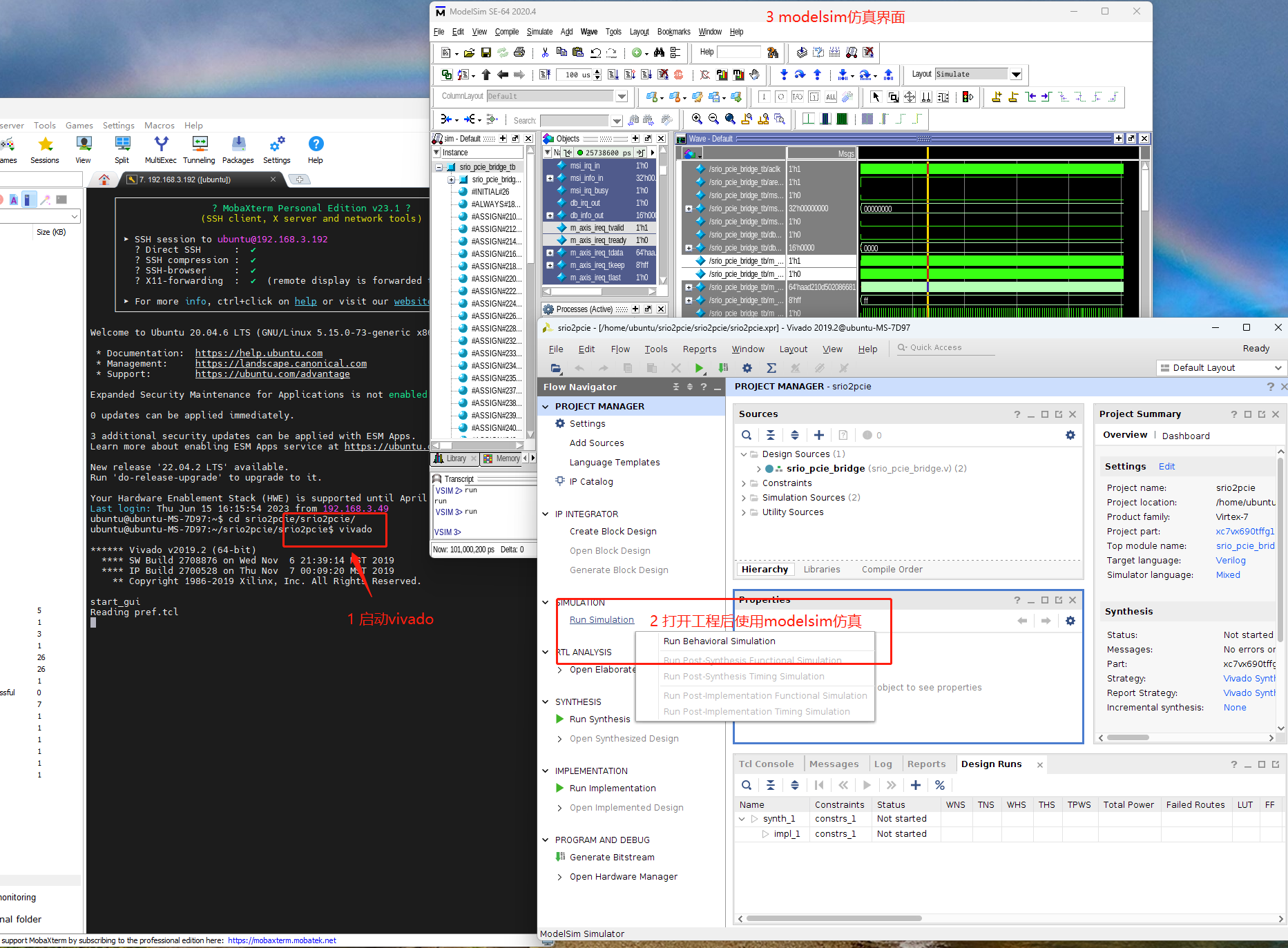
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
|
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
import time
import xlsxwriter
fp = open('linksTail.txt', 'r')
linksDict = {0:'RS0101', 1:'RS0102', 2:'RS0103', 3:'RS0104', 4:'RS0105', 5:'RS0106', 6:'RS0107',
7:'RS0108', 8:'RS0201', 9:'RS0202', 10:'RS0205', 11:'RS0206', 12:'RS0207', 13:'RS0208',
14:'RS0210', 15:'RS0211', 16:'RS0212', 17:'RS0213', 18:'RS0214', 19:'RS0215', 20:'RS0216',
21:'RS0217', 22:'RS0219', 23:'RS0220', 24:'RS0221', 25:'RS0222', 26:'RS0223', 27:'RS0224',
28:'RS0226', 29:'RS0227', 30:'RS0301', 31:'RS0302', 32:'RS0303', 33:'RS0304', 34:'RS0401',
35:'RS0402', 36:'RS0403', 37:'RS0404', 38:'RS0405', 39:'RS0406', 40:'RS0501', 41:'RS0502',
42:'RS0503', 43:'RS0504', 44:'RS0505', 45:'RS0506', 46:'RS0507', 47:'RS0508', 48:'RS0509',
49:'RS0510', 50:'RS0511', 51:'RS0512', 52:'RS0513', 53:'RS0515'}
driver = Edge()
for linkNum in range(54):
url = 'https://www.shanghairanking.cn/rankings/gras/2021/'+linksDict[linkNum]
driver.get(url)
time.sleep(1)
subjectObj = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[1]/div[1]/div[3]')
subjectName = subjectObj.text
print('Start of '+subjectName)
Workbook = xlsxwriter.Workbook(subjectName+'.xlsx')
Sheet = Workbook.add_worksheet()
Sheet.write(0, 0, '排名')
Sheet.write(0, 1, '学校名称')
Sheet.write(0, 2, '国家/地区')
Sheet.write(0, 3, '总分')
Sheet.write(0, 4, '重要期刊论文数')
Sheet.write(0, 5, '论文标准化影响力')
Sheet.write(0, 6, '国际合作论文比例')
Sheet.write(0, 7, '顶尖期刊论文数')
Sheet.write(0, 8, '教师获权威奖项数')
lastRow = 1
page = 1
while True:
currentRow = lastRow
for itemIndx in range(1, 31, 1):
try:
subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']')
except:
break
subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[1]/div')
Sheet.write(currentRow, 0, subItem.text)
subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[2]/div/div[2]/div')
Sheet.write(currentRow, 1, subItem.text)
subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[3]')
Sheet.write(currentRow, 2, subItem.text)
subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[4]')
Sheet.write(currentRow, 3, subItem.text)
currentRow = currentRow + 1
for scoreIndx in range(1, 6, 1):
currentRow = lastRow
scoreSel = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/thead/tr/th[5]/div/div[1]/div[1]')
driver.execute_script('arguments[0].click();', scoreSel)
time.sleep(1)
score = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/thead/tr/th[5]/div/div[1]/div[2]/ul/li['+str(scoreIndx)+']')
scoreName = score.text
driver.execute_script('arguments[0].click();', score)
time.sleep(1)
for itemIndx in range(1, 31, 1):
try:
subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']')
except:
break
subItem = driver.find_element(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr['+str(itemIndx)+']/td[5]')
Sheet.write(currentRow, scoreIndx+3, subItem.text)
currentRow = currentRow + 1
lastRow = currentRow
print('page ' + str(page) + ' finished!')
page = page + 1
nextPageLoc = 3
while True:
nextPage = driver.find_element(By.XPATH, '//*[@id="content-box"]/ul/li['+str(nextPageLoc)+']')
attr = nextPage.get_attribute('title')
if attr == '下一页':
break
nextPageLoc = nextPageLoc + 1
attr = nextPage.get_attribute('aria-disabled')
if attr == 'true':
break
driver.execute_script('arguments[0].click();', nextPage)
time.sleep(1)
Workbook.close()
print('End of '+subjectName)
driver.close()
|