实现这一个功能主要用到了selenium、mitmproxy和wechatarticles,利用selenium可以实现脚本模拟浏览器访问,mitmproxy配合wechatarticles获取文章信息。
参考文章:
selenium
selenium有一个官网,建议通过官网的教程入门。Getting Started主要有两步(我用的是python),一个是安装python的包,另一个就是还要下载浏览器的驱动文件,并且设置好环境变量。
mitmproxy
mitmproxy也有一个官网,在官网文档里的Getting Started里面写了,它默认监听本地的8080端口。有了这个代理,我们就可以获取网络传输中的数据包,要把它用起来就需要对代理进行设置。因为后面需要微信客户端的数据包收发进行监听,所以我直接对系统的代理进行了设置。
可以直接在windows桌面的搜索栏中搜索“代理”,就可以找到“代理服务器设置”,然后手动如图设置代理即可。
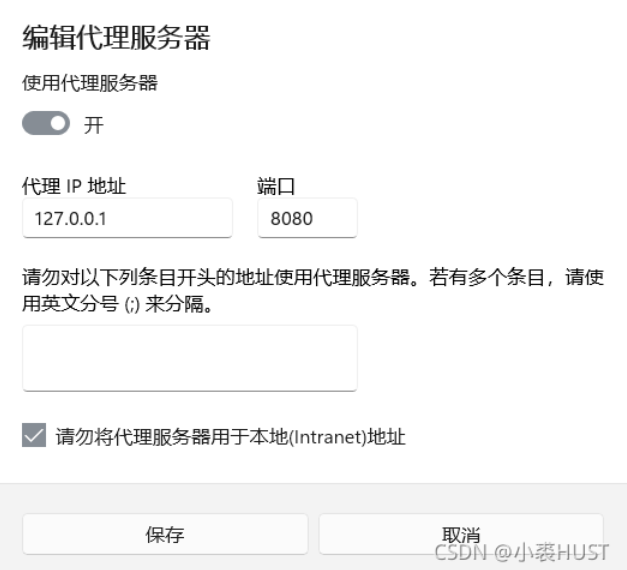
具体实现流程
具体步骤分为两步:
flowchart LR
s1(获取所有文章链接)-->s2(通过文章链接获取具体文章信息)
文章链接获取
按照上面第一篇参考文章中的方法,获取文章链接。值得一提的是,只要有微信和一个邮箱,就可以注册一个订阅号。这个邮箱绑定了订阅号之后就不能用来绑定其他的东西了,比如小程序。就一开始我的微信用一个邮箱绑定了一个小程序,然后微信登录的时候一直只有小程序的选项。这个时候其实只需要再搞一个邮箱,然后注册一个订阅号就可以了。
公众号管理界面可能跟上面文章中所说的不一样了,但实际上变化不大,还是只需要通过创建新的图文消息,来进入公众号文章链接引用的界面。
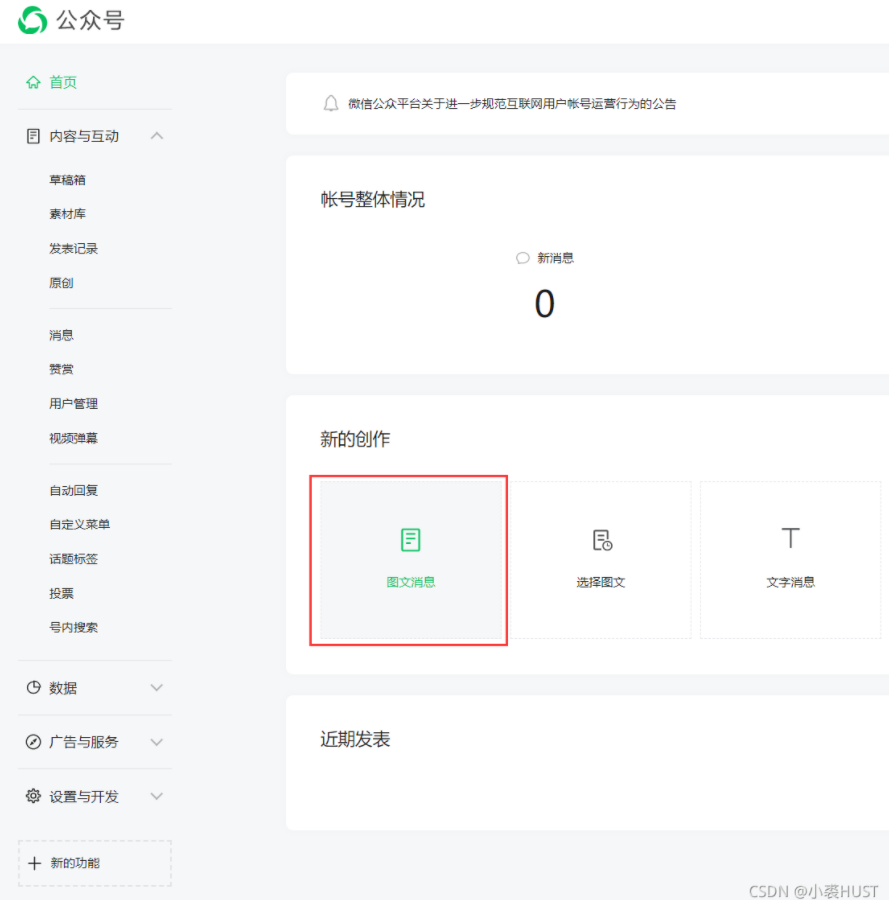
利用login.py和get_article_link.py两个文件获取所有文章链接。首先用login.py获取cookies,再用get_articleInfo.py获取文章链接。在使用的时候发现,这个网页也有反爬的机制,出现错误之后就等几个小时再继续。
和参考的文章中不一样的地方在于,我用的是Edge浏览器,然后在获取文章链接的同时还获取了文章的发布时间。具体的参数需要参考原文。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
from selenium import webdriver
import time
import json
driver = webdriver.Edge()
driver.get("https://mp.weixin.qq.com/")
driver.find_element_by_link_text("使用帐号登录").click()
driver.find_element_by_name("account").clear()
driver.find_element_by_name("account").send_keys("帐号")
time.sleep(2)
driver.find_element_by_name("password").clear()
driver.find_element_by_name("password").send_keys("密码")
driver.find_element_by_class_name("icon_checkbox").click()
time.sleep(2)
driver.find_element_by_class_name("btn_login").click()
time.sleep(15)
cookies = driver.get_cookies()
print(cookies)
cookie = {}
for items in cookies:
cookie[items.get("name")] = items.get("value")
with open('cookies.txt', "w") as file:
file.write(json.dumps(cookie))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
import requests
import json
import re
import time
with open("cookies.txt", "r") as file:
cookie = file.read()
cookies = json.loads(cookie)
url = "https://mp.weixin.qq.com"
response = requests.get(url, cookies=cookies)
print(response.url)
token = re.findall(r'token=(\d+)', str(response.url))[0]
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50",
"Referer": "https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=77&createType=0&token="+token+"&lang=zh_CN",
"Host": "mp.weixin.qq.com",
}
with open('article_link.txt', "w", encoding='utf-8') as file:
for j in range(1, 53, 1):
begin = (j-1)*5
requestUrl = "https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin="+str(begin)+"&count=5&fakeid=MzU4MjY2OTY2NQ==&type=9&query=&token="+token+"&lang=zh_CN&f=json&ajax=1"
search_response = requests.get(requestUrl, cookies=cookies, headers=headers)
re_text = search_response.json()
list = re_text.get("app_msg_list")
for i in list:
timestr = i["create_time"]
timeArray = time.localtime(int(timestr))
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
file.write(i["aid"]+"<=====>"+i["title"]+"<=====>"+i["link"] + "<=====>" + otherStyleTime + "\n")
print(i["aid"]+"<=====>"+i["title"]+"<=====>"+i["link"] + "<=====>" + otherStyleTime)
time.sleep(20)
|
获得的文本文件,可以导入Excel做成表格。在Excel中选择从文本导入数据,分隔符设置为“<=====>”。我在导入的时候遇到了一点问题,就有些地方它不识别这个分割符号。我就把这个“<=====>”,在文本文件中全部替换成分号,再用Excel导入就没问题了。
获取文章信息
获取文章信息是参考第二和第三篇文章做的。想要获取微信公众号文章的阅读量、点赞等信息,在浏览器中打开微信公众号文章是没有用的。只有通过微信打开才能拿到这些信息。所以在第三篇文章中,原作者就搞了一个自动控制微信的脚本,在文件传输助手中点击文章链接来产生带cookie和appmsg_token的包。但如果文章数量比较少,其实可以手动点。经过测试,每次获得的cookie和appmsg_token至少可以用来获取100篇文章的信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import urllib
import sys
from mitmproxy import ctx
from mitmproxy import io, http
class WriterCookie:
"""
mitmproxy的监听脚本,写入cookie和url到文件
"""
def __init__(self,outfile: str) -> None:
self.f = open(outfile, "w")
def response(self, flow: http.HTTPFlow) -> None:
"""
完整的response响应
:param flow: flow实例,
"""
url = urllib.parse.unquote(flow.request.url)
if "mp.weixin.qq.com/mp/getappmsgext" in url:
self.f.write(url + '\n')
self.f.write(str(flow.request.cookies))
self.f.close()
exit()
addons = [WriterCookie(sys.argv[4])]
|
write_cookies.py是mitmproxy的监听脚本,可以从下面的命令看出来,当它监听到 “mp.weixin.qq.com/mp/getappmsgext” 这种请求包时,就把请求包的内容保存下来。这种请求就是每次微信打开公众号文章是发出的请求包。
1
| "mitmdump -s {}/write_cookies.py -w {} mp.weixin.qq.com/mp/getappmsgext".format('./cookie.txt')
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
import re
import os
import threading
from wechatarticles import ArticlesInfo
import time
class ReadCookie(object):
"""
启动write_cookie.py 和 解析cookie文件,
"""
def __init__(self,outfile):
self.outfile = outfile
print(self.outfile)
def parse_cookie(self):
"""
解析cookie
:return: appmsg_token, biz, cookie_str·
"""
with open(self.outfile) as f:
data = f.read()
appmsg_token_string = re.findall("appmsg_token.+?&", data)[0].split('=')[1]
cookies = re.findall(r"\['(.*?)'\]", data)
Wechat_cookies = {}
for cookie in cookies:
cookie = cookie.split("', '")
Wechat_cookies[cookie[0]] = cookie[1]
return appmsg_token_string,Wechat_cookies
def write_cookie(self):
"""
启动 write_cookies。py
:return:
"""
path = os.path.split(os.path.realpath(__file__))[0]
print(path)
command = "mitmdump -s {}/write_cookies.py -w {} mp.weixin.qq.com/mp/getappmsgext".format(
path,self.outfile)
os.system(command)
def get_cookie():
rc = ReadCookie('cookie.txt')
rc.write_cookie()
appmsg_token_string, cookies = rc.parse_cookie()
return appmsg_token_string, cookies
fp_src = open('links.txt', 'r')
fp_dst = open('articleInfo.txt', 'w')
count = 0
while True:
appmsg_token, cookies = get_cookie()
cookie = ''
for ck in cookies.items():
if not cookie:
cookie = cookie + ck[0] + '=' + ck[1]
else:
cookie = cookie + '; ' + ck[0] + '=' + ck[1]
print(cookie)
for i in range(100):
url = fp_src.readline()
if not url:
break
article_url = url
test = ArticlesInfo(appmsg_token, cookie)
read_num, like_num, old_like_num = test.read_like_nums(article_url)
count = count + 1
print(str(count) + " read_like_num:", read_num, like_num, old_like_num)
fp_dst.write(str(read_num) + ';' + str(like_num) + ';' + str(old_like_num) + '\n')
time.sleep(3)
|
对监听到的包解析之后就可以获取我们需要的cookie和appmsg_token,然后那这个去获取微信公众号的文章信息,重复100次后,再去更新cookie和appmsg_token。在此之前,我已经事先把所有文章的链接都存到了一个文本文件“links.txt”中,每次都从里面读一行就是一个文章链接。
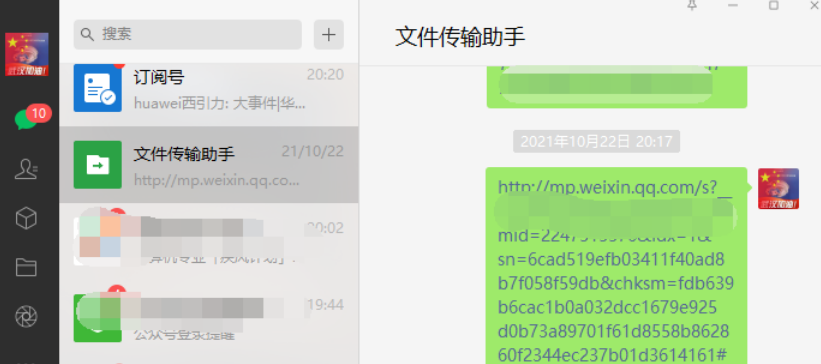
然后每到100条记录之后,我就手动点这个文件传输窗口中的链接,就是每次命令行提示下面的信息的时候,我就点一下上面文件传输助手中的链接来更新cookie和appmsg_token。