类脑计算论文泛读
上学期听了何毓辉老师的《类脑计算与器件》课程,本文也是对上学期上课内容的大体总结。
参考文献:
- [1] Nature Communications 2017, Face classification using electronic synapses
- [2] Nature 2015, Training andoperation of an integrated neuromorphic network based on metal-oxide memristors
- [3] IEDM 2015, Experimental demonstration and tolerancing of a large-scale neural network (165,000 synapses), using phase-change memory as the synaptic weight element
- [4] TNNLS 2015, Supervised Learning Using Spike-Timing-Dependent Plasticity of Memristive Synapses
- [5] IEDM 2019, Complementary Graphene-Ferroelectric Transistors (C-GFTs) as Synapses with Modulatable Plasticity for Supervised Learning
- [6] VLSI 2016, Novel RRAM-enabled 1T1R synapse capable of low-power STDP via burst-mode communication and real-time unsupervised machine learning
- [7] Nature Electronics 2019, Reinforcement learning with analogue memristor arrays
- [8] IJCNN 2016, Memristor Crossbar Deep Network Implementation Based on a Convolutional Neural Network
- [9] IJCNN 2017, Extremely Parallel Memristor Crossbar Architecture for Convolutional Neural Network Implementation
- [10] Nature Nanotechnology 2017, Sparse coding with memristor networks
忆阻器
忆阻器是一种统称,它一般指电导可以连续调节,并且调节结果可以保存的器件。主要有:阻变存储器、相变存储器、铁电晶体管、浮栅晶体管等。

阻变存储器以氧化铪为例,它有一半低阻区(LR)一半高阻区(HR)。在两端加较小的电压时,LR和HR之间的界面几乎不会移动;加比较大的电压时,会有氧空位(Oxygen Vacancies)在界面之间移动,造成界面的漂移。LR区域越多,整体的电导越大,反之HR区域越多,电导越小。外加电压与电导的调整量不是线性关系,外加电压主要加在HR区域上,随着HR区域的减小,HR区域中的场强会越来越大,氧空位移动速度会加快。除此之外,氧空位自己也会发生漂移,这为器件带来了很大的随机性。
相变存储器(Phase Change Memory,PCM),是依靠晶态与非晶态的变化来改变电导的一种器件。它从非晶态(amorphous)向晶态(cubic)变化时,电导值可以连续增加,但是从晶态到非晶态的过程中电导是突变的,这和它的物理机制有关。

从非晶态到晶态的过程称为“annealing”,对应上图中的加Set温度曲线,温度要超过结晶温度,但不能到达熔融温度。从晶态到非晶态的过程称为“melt-quenching”,需要将温度身高到熔融温度,并快速降温,对应图中的Reset曲线。
那么如何做到对器件的温度控制呢?实际上就相当于电阻发热,发热功率是,所以在读PCM的电导值是,外加一个小电压,也会产生一定的热效应,对应图中的Read曲线。
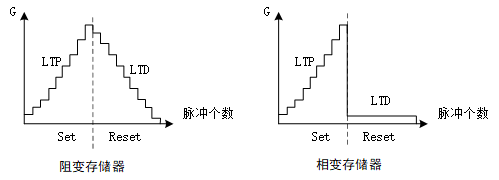
用于人工神经网路的忆阻器,我们比较关心它的线性度。长时增强效应(long term potentiation, LTP)和长时抑制效应(long term depression,LTD)是两个重要的衡量指标。阻变存储器的LTP和LTD虽然可能没有上图中那么线性,但大体还是有缓慢增加或减少的趋势,而相变存储器的LTD则是电导值始终位置在较低的水平。
铁电晶体管与浮栅晶体管的原理类似。浮栅晶体管是Nand Flash的基本构成单元,它的栅介质层中有一个“浮栅”,主要材料是多晶硅。在外加电压作用下,衬底电荷利用隧穿效应可以在浮栅与衬底之间穿梭,电荷能够留存在浮栅中,起到保存沟道电导值的目的。铁电晶体管的栅介质层是铁电材料,它可以被外加电压极化,并维持极化的状态。
1T1R突触结构
论文[1]中介绍了利用1个晶体管+1个RRAM作为突触,利用感知机模型实现人脸分类。人脸图像20×16个像素,训练样本包含三个不同的人的人脸。
从算法层面说,每个样本320维,权值也是320维,每个样本带有一个标签,将样本送入感知机,得到结果,与预期结果对比,利用梯度下降法更新权值。感知机模型中用的符号函数不是连续可导的,不能用梯度下降法,因此可以用双曲正切函数近似。
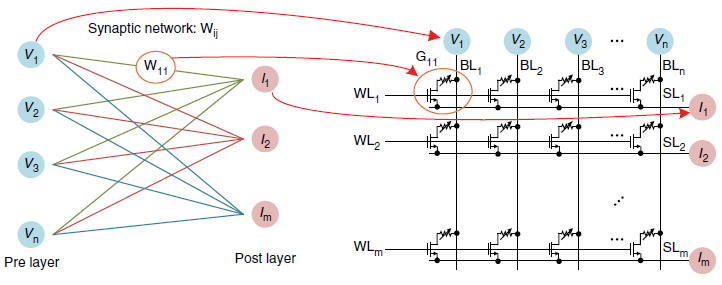
但从算法方面考虑这一问题比较简单,硬件实现会有一些额外的问题。在硬件上,每个突触与一个权值对应。突触阵列能够方便地完成向量矩阵乘法(VMM),因为它是并行的乘加运算。所以RRAM阵列很适合用来做前向推理,但是更新权值比较麻烦。
它非常依赖外部的计算资源,比如梯度下降法计算权值的更新量,这是在阵列外部完成的,我们需要考虑更改权值也就是突触电导值的策略。
| 层面 | 法则1 | 法则2 |
|---|---|---|
| 算法 | Delta Rule | Manhattan Rule |
| 硬件 | Write with Verify | Wirte without Verify |
主要有两种方式,“Delta Rule”就是精准改变权值,计算出需要改变多少就改变多少。而前面提到RRAM的电导调整是非线性的,因此每次改电导值都需要再读出来确认是否改到位了。 另一种方式是“Manhattan Rule”,它只关心权值改变的方向,比如需要增大,那么这次修改就增大一次对应的电导值,而不关心实际电导变为了多少。后者因为没有验证权值更新的过程,所以相对来说需要更多的样本才能收敛,前者在修改单个权值时是do-while循环,时间不可控,而后者每次修改单个权值不需要循环,非常快。从总的时间上来说前者需要的时间更多,但考虑到功耗和训练结果等指标后,前者的性能更好。
还有“Online learning”和“Batch learning”的概念的区分。人工神经网络通常采用Batch learing。Batch learning需要一次性输入一批数据,然后把每个权值的权重改变量累加。这样做使得每次权重调整更容易找到整体的梯度下降最快的方向,缺点是需要对一批数据进行存储。而Online learning则是每次输入一个样本就调整一次权重,与Batch learning相比不需要暂存权重改变量,但是它需要对权值调整很多次,而且不同的样本输入顺序可能会得到不同的学习结果。
人工神经网络所采用的的器件的耐久是有限的,不管是浮栅晶体管的隧穿效应还是RRAM内的晶格碰撞,都会损害器件的寿命。所以人们一般希望对权重的改写次数少一些,所以采用Batch learning的策略较多。
忆阻器件作为神经网络突触还会考虑到很多因素。multilevels和retention之间有一个trade-off。multilevels和神经网络的训练精度有关,因为一个特定的能态对应于一个突触的权值,在一定范围内能态越多,权值的精度越高。随着能态的增多,能态之间的间隔越来越小,容易发生隧穿,所以它的保持特性retention会比较差。还有器件的variation也是一个比较严重的问题,variation包括Part to Part(aka. PtP) variation和Device to Device(aka. DtD) variation。但就像大脑有代偿能力,神经网络里的一个突触如果出了问题,还有其它突触也能够进行补偿。
潜行通路
1T1R用一个晶体管来选通RRAM,实际上一个晶体管的面积非常大,所以我们可以想办法把晶体管省去。但如果仅仅是把晶体管省去,就会引入潜行通路的问题。
在存在晶体管的时候,晶体管起到选通的作用。利用晶体管的导通和关断可以同时对多个RRAM调整电导值。没有了晶体管之后就只能逐个对单个突触的电导值进行修改。相当于用一根字线和一根位线选中一个bit,而其余字线和位线都悬空。之所以悬空而不是接固定电平是出于功耗的考虑,这一悬空带来的问题就是潜行通路。
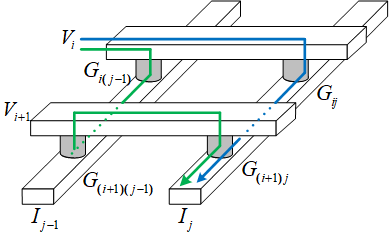
如上图所示,我们希望只通过蓝色的路线对有贡献,但实际上由于悬空,还会通过绿色的路线对产生贡献,这就是潜行通路(sneak path)。
1S1R突触结构
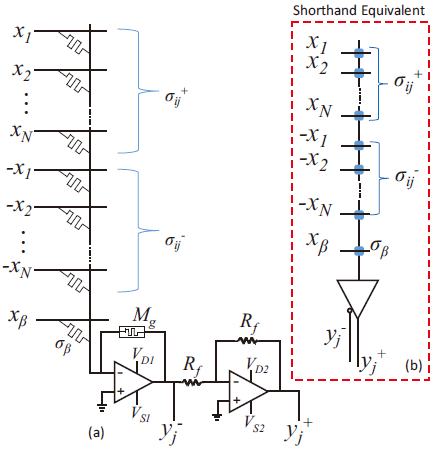
针对潜行通路的问题主要有两种办法,一种是用类似二极管的器件切断潜行通路,另一种是用差分对的结构进行补偿。这里先介绍第一种,就是1S1R的结构。
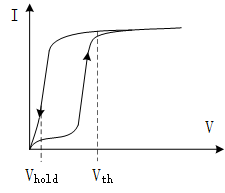
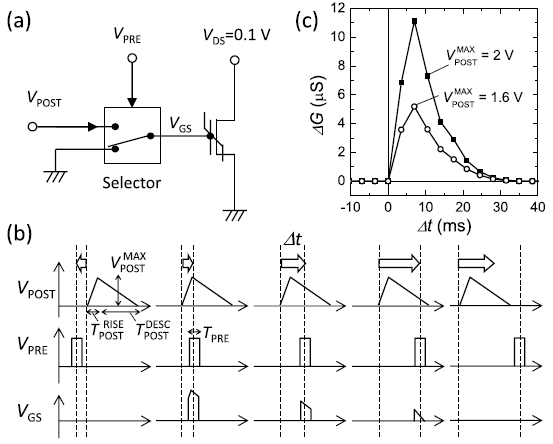
1S1R中的S指的是选通管(Selector),它是一种类似二极管的器件,但相比于二极管,它的正向导通压降更低(几乎没有),它的传输特性曲线如上图所示。它的一个重要的特性就是它导通后,只要电压不低于就能维持在低阻态。
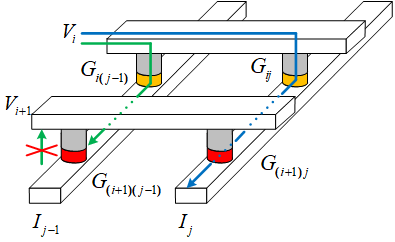
选通管几乎不会占用多余的面积,它与RRAM的工艺兼容性更好。如上图所示,它能够直接切断潜行通路。
差分对突触结构
第二种解决潜行通路的办法是引入差分对。
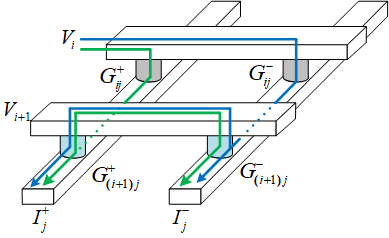
用两个突触电导的差来代表权重。
对于电流,我们可以把它的组成分为三类,一类是仅通过产生的电流;一类是经过所在路径的潜行通路电流,注意这部分电流不只图中画的蓝色部分,类似蓝色部分的电流还有好多条,可以把这部分电流对应的电导记作;最后一类是通过其它的潜行通路产生的电流,记作。
当输入向量维度比较大时,可以把和看做近似相等,那么:
这样就抵消了潜行通路的影响。论文[2]就是采用了这样的设计方法。
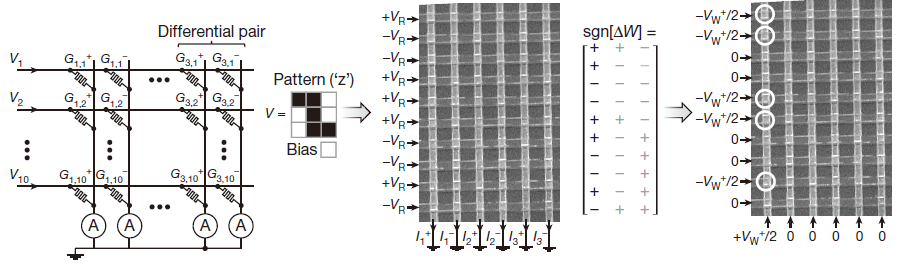
文中作者实现了对“Z”、“V”、“R”三种模式的识别,每个字母都是一个3×3的样本。值得注意的技巧是,作者改写电导值用的“半电压”。写电压为,在突触两端分别施加和来达到改写电导值的目的,这么做有利于降低功耗。
还有一个需要考虑的问题是,现在是由两个数相减得到的,当我需要增大时,是增大被减数还是减小减数?这个和器件的LTP、LTD有关。比如PCM的LTD反应出它的电导值不能连续减小,因此它不适合采用减小减数的方法。
器件的电导值是有界的,比如我采用PCM作为突触,增大权重采用增大的方法,减小权重采用增大的方法,那么它们俩的电导值肯定在一段时间后会达到极限。因此需要每过一段时间将读出,然后将电导值都复位,重新将差值写入或。
反向传播
反向传播的思想非常简单,利用梯度下降法令损失最小。
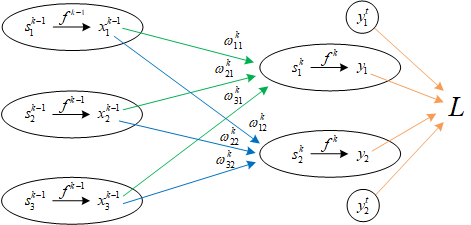
上图是传统神经网络的最后一层,第k层。每有一组权值矩阵称为一层。权值矩阵的改变正比于当前在损失函数上的梯度。
为了简化推导,先约定一些记号:
写出关于的全微分式:
这么直接求梯度没法求,需要分解步骤。
引入中间变量,是1×2的列向量。又因为是标量,所以可以直接对右边求迹。
对比前后两个全微分表达式可以得出:
从上面这个梯度计算结果来看,梯度大小只和当前层的输入和损失函数对求和结果的偏导数有关。这不光是对最后一层成立,对其余层也都成立。
每一层的输入都是已知的,关键是怎么求?定义第k层的损失误差。我们从最后一层开始,最后一层是最容易求的。
计算k-1层的损失误差:
这样就得到了一个关于的递推公式,这也是“反向传播”这一名称的由来。损失误差可以逐层从后向前计算。
利用器件实现反向传播的优势在于,可以利用RRAM阵列很快地计算出。因为是由一个列向量和一个行向量相乘得到的,可以把它们直接从行列方向送入阵列。
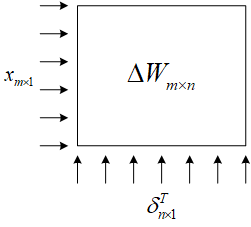
光有这样的结构还不行,还需要对输入的数据进行编码。
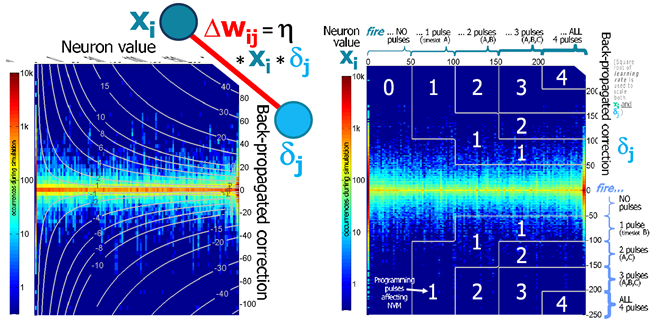
这里截取了论文[3]中的两张图,左边的是算法层面的,和都是连续值。而右图是将和做了脉冲编码,这里举的例子是将量化为5个等级。两者都采用半电压输入,只有两者的脉冲同时有效时才能凑成一个完成的写电压。
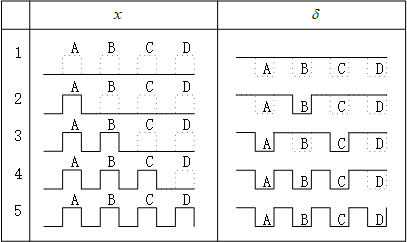
上图是脉冲和的脉冲编码方式。
脉冲神经网络
STDP
Spike Timing Dependent Plasticity,是生物大脑内的一种学习规则。
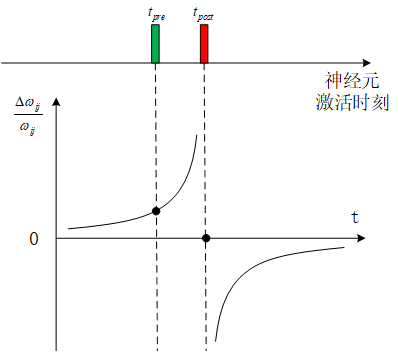
是前一个神经元被激活的时刻,是后一个神经元被激活的时刻,神经元之间突触权值的变化量与前后神经元激活时刻的时间差有关。概括起来说就是,时间越近响应越强。
漏电积分点火神经元模型
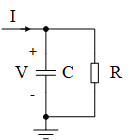
生物细胞中神经元之间的信息传递是依靠钠钾离子的转移改变细胞膜电位实现的。利用一个电容和一个电阻可以建立起这样一个模型,神经元的激活可以用电容两端电压的暂态响应来描述。
在这个电路中,一方面有电阻漏电,另一方面电容对输入电流进行积分。所以称之为“漏电积分点火神经元”(Leaky Integrate-and-Fire neuron, LIF neuron)
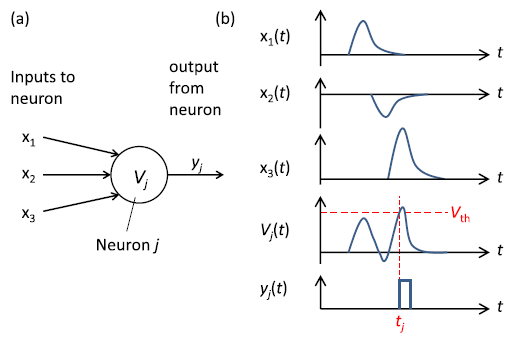
这是来自论文[4]中的一张截图。它展示了当电容上的电压达到一定的阈值时,这个神经元就会产生一个脉冲信号,表示它被激活。
实现SNN主要有两种结构,一种是SprikeProp另一种是ReSuMe。
SpikeProp
用表示神经元脉冲响应函数。
建立输入层、一层隐藏层、输出层,构成脉冲神经网络。有两层权重需要调整,和。利用梯度下降法经过复杂的计算可以得到近似结果。
权重变化量主要受到两部分控制。一部分是期望的脉冲产生时刻和实际脉冲产生时刻的差值;另一部分是前级脉冲输入时刻实际脉冲产生时刻的差值对应的权值改变量,这一部分满足STDP规则。
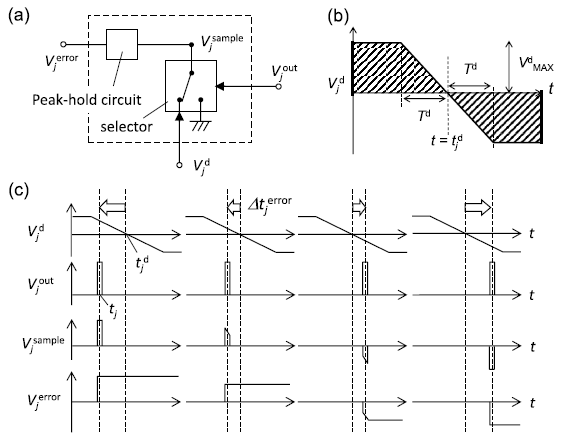
有一个问题是时间量纲的转换。以为例,当早于,电容充电太快,需要减小电导,因此此时的需要对应一个正电压,如上图左侧的脉冲所示;反之当晚于,需要用电压保持器保持一个负电压,用于后续信号生成。
下面框图中的Error signal(DC)就是由前面的电压保持电路生成的误差信号。D/A根据误差信号生成Post-pulse3,这一步相当于完成了乘法,再由输入脉冲Pre-pulse2来采样这个电压波形就能够得到对应的电压,并施加到铁电存储器的栅极上。
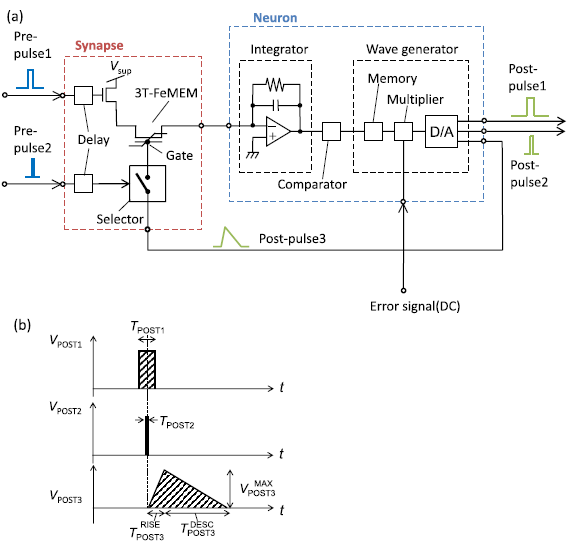
基于三端铁电存储器的突触和LIF神经元电路框图如上图所示。采用三端忆阻器件,使得读写可以同时进行。图中只画出了一个突触,实际上一般会有多个突触同时接到一个神经元上。
这个框图应该这么看,在神经元没有被“点火”的情况下,神经元不断地对电流积分,此时还不涉及对突触权重的调整。一旦神经元被“点火”,就会有Post-pulse3信号产生,各个突触的电导会根据STDP法则调整,输入脉冲时刻越接近神经元被点火的时刻,那么对应的突触电导提升得就越大。Pre-pulse1和Pre-pulse2输入端还有延时单元,是为了补偿后级电路的延时,使得Pre-pulse2和Post-pulse3在时序上能够对应上。
上图展示了电压采样的过程,有两个自由度可以调整,一个是调节本身的大小,另一个是采样时刻,对应了的计算过程。
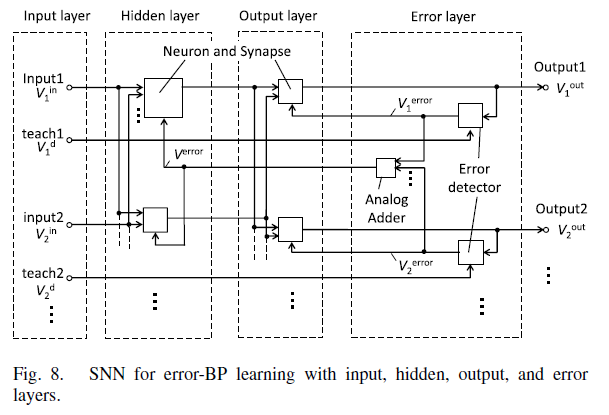
是输入层和隐藏层之间的权重,这一层的误差需要对输出层的误差进行累加,如上图所示。这里除了送入神经元的误差信号与前面不同以外,别的都是一样的。
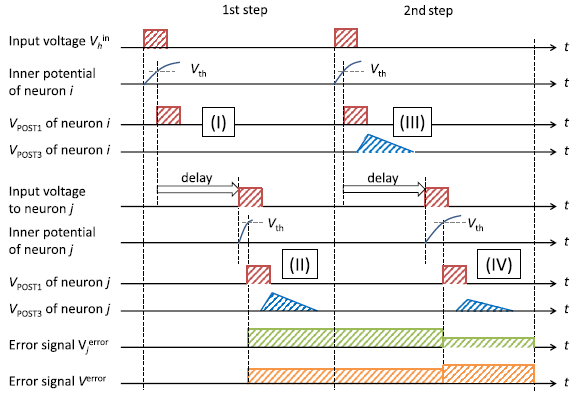
由于误差信号是在输出层产生的,在第一次输入样本的的时候,误差信号并没有产生,因此需要将同一个样本输入两次才能正确更新两层权重。这里是两层神经网络,需要把样本送入两边,那么如果是n层神经网络,需要重复送入几遍?答案还是两遍,因为我们在第一次输入的时候就能获得每一层的误差。
ReSuMe
SpikeProp的推导相对来说比较复杂,Remote Supervised Method,ReSuMe是另一种较为简单的实现SNN的方式。
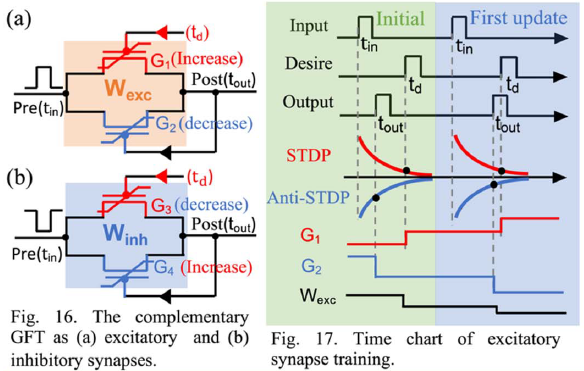
论文[5]提出了一种用互补石墨烯铁电晶体管(C-GFTs)实现的方案。ReSuMe的基本思想是由两个忆阻器件组成突触,整体电导值是两者之和。其中一个负责增大电导,另一个负责减小电导。
在输入脉冲到来时产生一个STDP曲线和一个Anti-STDP曲线,在期望脉冲产生的时刻采样STDP曲线,增大电导;在和输出脉冲产生的时刻采样Anti-STDP曲线,减小电导。
这样只有在期望脉冲产生时刻和实际脉冲产生时刻重合是才不会改变电导值;脉冲产生时刻超前,则减小电导的作用明显;脉冲产生时刻滞后,则增大电导的作用明显。
有个值得一提的技巧是,如果始终单向调整电导值,很有可能很快会达到极限。而这里有一个简单的刷新方案,因为两个电导值是相加的关系,所以可以直接交换两个电导的更新方式。原本负责增大电导的忆阻器负责减小电导;原本负责减小电导的忆阻器负责增大电导。
应用
SNN适合结合动态视觉传感器(Dynamic Vision Sensors, DVS)使用。一个像素由亮变暗和由暗变亮会产生不同的脉冲。在一幅图上构建两张突触网络,一张展现由有亮变暗的像素点,一张展现由暗变亮的像素点。将两者结合起来看就可以看出物体的运动方向。
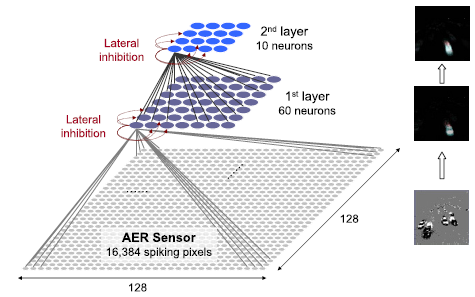
上图截自2012 Neural Networks的Extraction of temporally correlated features from dynamic vision sensors with spike-timing-dependent plasticity,图像数据的表示方式是Address-Event Representation, AER。只有发生明暗变化才会发送数据,比较适合监控场景。
非监督学习
论文[6]用1T1R的突触结构实现了手写数字识别的非监督学习。它也是遵循STDP的学习法则。只是做了简化,下图是权值改变曲线,它是STDP曲线的一级近似。当后级神经元的脉冲在前级神经元的脉冲之后10ms内产生,则增大权值;反之减小权值。
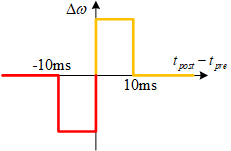
神经元的输出是宽度为10ms的高电平+10ms的低电平,加在后级突触的晶体管栅极。这意味着在神经元被激活之后的10ms内,其后级的突触电导能够被读或者被改写。
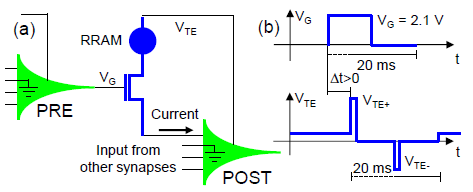
RRAM的一端接,叫做Top Electrode,在平常是固定的高电平读电压。前级神经元产生的脉冲会产生读电流,后级神经元不断积分。而在后级神经元被激活的时候,后级神经元会发出一对正负脉冲加载上,用来改电导值。正脉冲位于前10ms内,负脉冲位于后10ms内。这一简单的设计就实现了时,正脉冲在窗口期内;时,负脉冲在窗口期内。
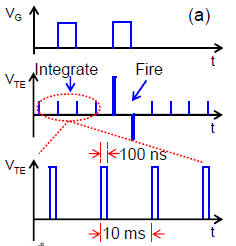
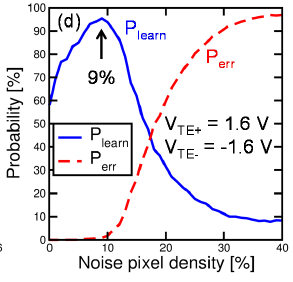
上图是它实际工作的过程。最后的结果如下图所示,训练之后,10个输出神经元的突触权重正好构成了对应的数字。为了避免产生多个输出,输出神经元之间也有连接,在生物上称为“侧抑制”,“Lateral Inhibition”。也可以称之为“Winner Take All”。就是当其中一个神经元激活时,其它神经元的积分过程直接终止。

还有一个值得一提的地方是,训练的时候对背景的抑制也是训练成功的关键。在输入训练样本的时候同时交替输入一些噪声,能够提高学习的效率。这部分噪声产生的脉冲会抑制对应的背景的权值,使得训练效果更好。实验结果表面,引入9%的噪声能够达到最好的学习效率。
强化学习
强化学习也很大程度上依赖外部的计算资源,论文[7]是用数模混合的方式实现强化学习的一个例子,但它只是用模拟硬件做向量矩阵运算,在器件层面没有特别的地方。这里简单介绍强化学习的一些基本理论。
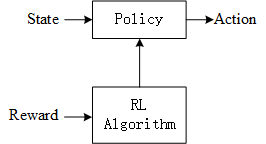
强化学习算法通过优化策略来使收益最大。把状态下,采取行动的概率记为,它满足:
把状态下,采取行动,转移到状态的奖励记作,采取某个策略的总收益记作。

上面这个收益相当于是目标函数,需要令其最大,据此优化策略。其中有一个折扣系数,它表示相比于以后的收益,我们更注重当前的收益。
在经典世界的前提下,只能取1或者0,此时还可以对这一目标函数简化。
所有的可以构成一张Q值表,强化学习的训练过程实际上就是Q值表的更新过程。其中部分用到向量矩阵乘法的计算就可以用忆阻阵列来实现。
卷积神经网络
论文[8]和论文[9]介绍了卷积神经网络相关的设计。全连接神经网络主要有两个问题。一个是参数特别多,但又是稀疏的;另一个是可诠释性的问题,隐藏层的突触含义不能直观地解释。卷积神经网络利用卷积核提取图像中的特征,可解释性强且参数少了很多。
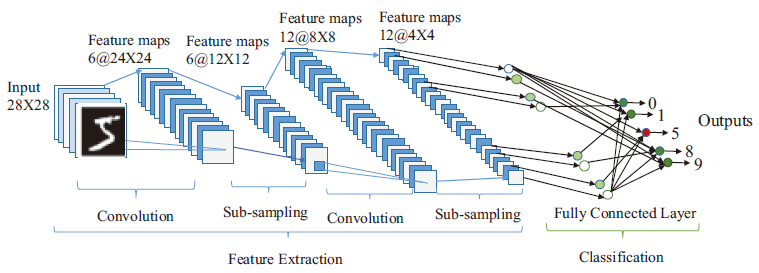
上图是一个典型的卷积神经网络的结构框图。包含卷积、降采样(池化)和全连接等操作。降采样能够有效防止过拟合。一般来说,n个卷积核能够得到n通道的特征图;卷积核的维度和将要参与运算的特征图的维度高一个维度。比如单张图像,卷积核就是二维的,但可以有多个,那就是三维;对于多通道的特征图,卷积核就是三维的,而且也可以有多个,那就是四维。
一般越靠近输入,卷积核越少;越靠近输出,卷积核越多。因为卷积核少是为了提取图像中最基本的特征,而后面可以将这些基本特征进行组合得到复杂的特征。
卷积神经网络的硬件实现,有两个个比较关键的问题是。一个是硬件适合处理的是向量矩阵乘法,一维向量乘以二维矩阵,而在CNN中,特征图和卷积核一般在三维及以上,很难用硬件处理。第二个问题是,卷积核是有正负的,如果单独控制每个突触上的电压施加方向将会非常麻烦。
针对第一个问题,论文[8]中作者将卷积核和特征图都拉成一维,多个卷积核可以构成二维的矩阵。卷积核是固定的,而令输入滑动,实现向量矩阵运算。

针对第二个问题,作者采用的方法是,将原本一个卷积核,分成两个卷积核,令正负计算结果分开。输入样本与正的卷积核卷积,输入样本取反后与负的卷积核卷积。这样做虽然花费了更大的面积,但是解决了卷积核包含正负的问题,而且可以多个卷积核并行计算。
卷积核的电导值是需要提前写好的。采用写Write with Verify 的方式,将当前电导值转换成电压信号读出,并利用两个DAC、一个比较器和几个逻辑门判断当前的电导值是否在一定的误差容限范围内,从而确保电导值写到位。
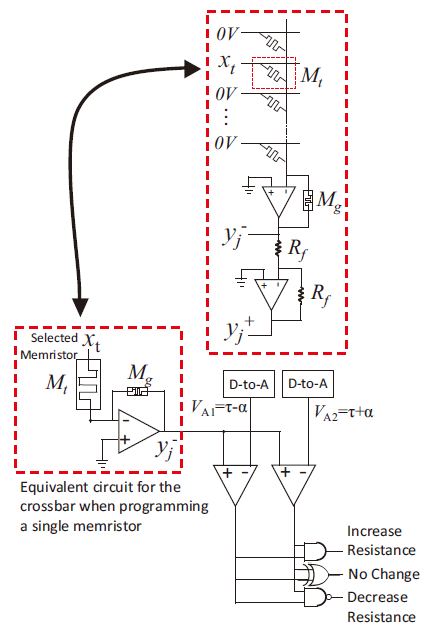
论文[9]提出了一种并行性更高的方案。因为论文[8]中的卷积是由输入特征图滑动输入得到的,所以需要一段时间。但其实也可以采用更大的面积来实现卷积核,用空间换时间,令卷积结果同时输出。
文中对一个4×4的图采用3×3的卷积核进行卷积,结果是2×2的特征图。可以从卷积核的四列直接得到结果。
将神经网络与强化学习结合,就有了深度Q值网络(Deep Q-Network, DQN)。原本的Q值表示离散的,有限的,遇到无限的state和action时,Q值表就不再适用,所以DQN就是完成了问题的泛化,对没有遇到过的state也能做出判断。这部分没有细看就不详细写了……
稀疏编码
协方差矩阵
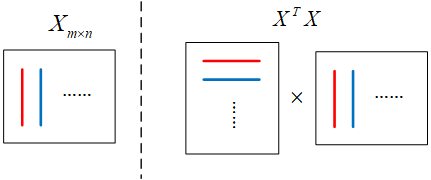
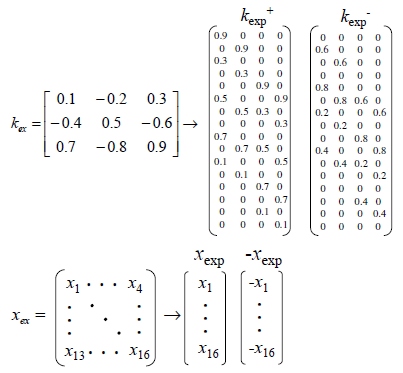
有m个n维的样本构成样本矩阵,注意样本是横放的,在上面的左图中,我为了突出同一列是同一种属性所以画了竖线。
样本间同一种属性的均值为0。对于同一个属性,m个样本可以看作m个随机变量,用样本均值代替期望值来计算方差和协方差。当均值为0时,方差和协方差的计算可以转换为向量内积的计算。
因此几乎就是协方差矩阵,只差除以,这个系数不影响我们定性分析数据。
的对角线元素代表样本每个维度的方差,数值越大表明样本在这个维度上的区分度最高;非对角元素表明了样本不同维度之间的相关性,数值的绝对值越大则相关性越高,数值的正负表现了正负相关性。
PCA
实对称矩阵一定可以相似对角化。
等式右边是由特征值组成的对角矩阵。可以理解为在某个空间坐标系下,这组样本的各个维度是不相关的(非对角元素为0),而对角元素中的最大值表明在这一维度上能够最明显地区分出这这组样本。
稀疏编码
人脑里就像是有一个“词典”,当我们认识一样事物,就会从里面拿出一些词来描述Ta。这个词典非常非常大,而我们每次只需要少量的词。
,包含很多0,是稀疏的。我们的目标是找到一个最好的,它既能准确地描述,又能用最少的词来表示,所以就得到了下面这个目标函数:
可以把这个字典做成忆阻阵列,向量矩阵乘法是向量在各个矩阵的列向量方向上的投影,我们要找一个合适的实际上就是将按照字典中的向量进行分解。
字典不一定是一个完备正交集,很可能字典里有两个词非常像,所以不能直接拿和相乘的结果的输出作为最终结果。在这里引入了LIF神经元,我们可以把那些激活的神经元作为系数编码的结果。
LCA
局域竞争算法(Locally Competitive Algorithm, LCA),是论文[10]中提出的一种方法,它利用协方差矩阵巧妙地抑制相似的词被激活。
先不看公式的后半部分,前面一半和LIF神经元的模型几乎一模一样。都是包含漏电项和积分项。

公式的后半部分包含,这里有个前提是的每个列向量都是已经归一化而且均值为0,因此的对角线上均为1,即使对角线上都是0的方阵,而非对角元素表示字典中不同的两个词之间的相关性。
是的稀疏表示,在刚开始的时候,的每个分量都是0。随着LIF的积分,其中一旦有一个神经元激活,就是达到了公式中这一条件。这个激活的神经元就会对其它和它相关的神经元产生抑制。而且抑制的程度由两方面决定。一方面是这个激活的神经元本身的电压,另一方面是不同的两个词之间的相关性。
阈值的选取非常重要,越小,中的词越多,但因为不是正交完备的,所以可能会有矛盾的词被同时激活,所以这样的对的描述反而不会很准确;越大,中的词越少,词太少也无法准确描述。所以只有选取合适的阈值才行。
上面的式子可以重写,把后半部分的括号展开,可以写成由根据重构的,记作。
原来的式子就可以写成:
这里可以将侧向抑制重新理解为,一个已经建立的稀疏描述会将输入中包含的这部分特征移除。