参考资料
- SPRU198K-TMS320C6000 Programmer’s Guide
- SPRUGH7-TMS320C66x DSP CPU and Instruction Set Reference Guide
主要是看了SPRU198K这个文档里的第三章,这一章里有5个Lesson,非常详细地介绍了一些很实用地优化方法。
在看这个之前最好对DSP数据路径和功能单元有了解,可以看SPRUGH7这个文档。只有充分发挥出8个功能单元的性能才能说是开发DSP,不然就只是单纯的C/C++开发。哦!还有我觉得起始看第三章之前可以先看一下第四章,第四章介绍了编译器反馈给用户的汇编文件中的一些短语的含义。
一些准备
DSP优化的过程并不是自己去写汇编而是尽可能多地告诉编译器一些信息,让编译器帮我们优化。
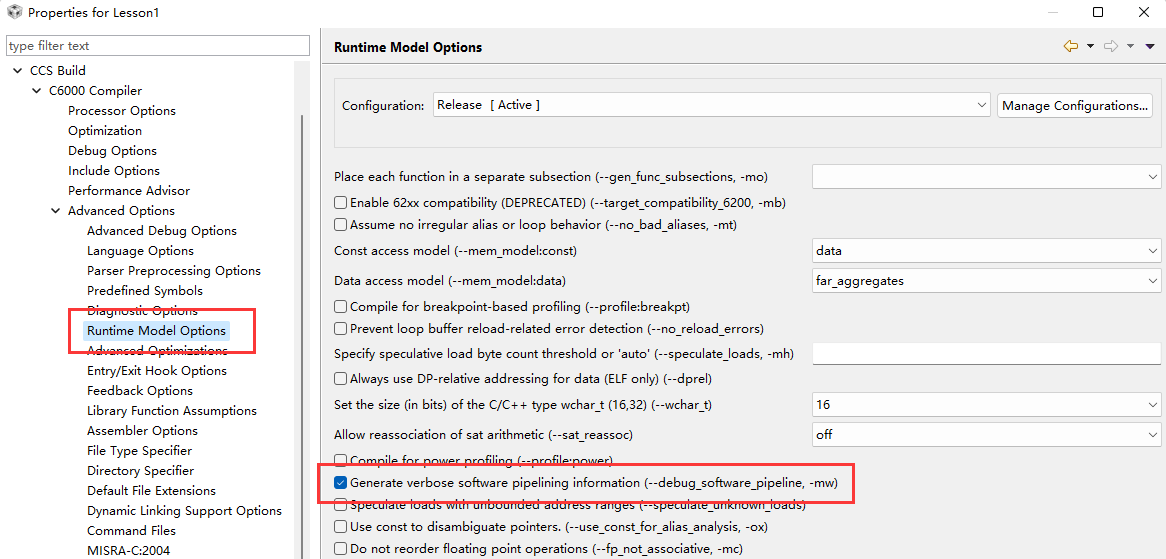
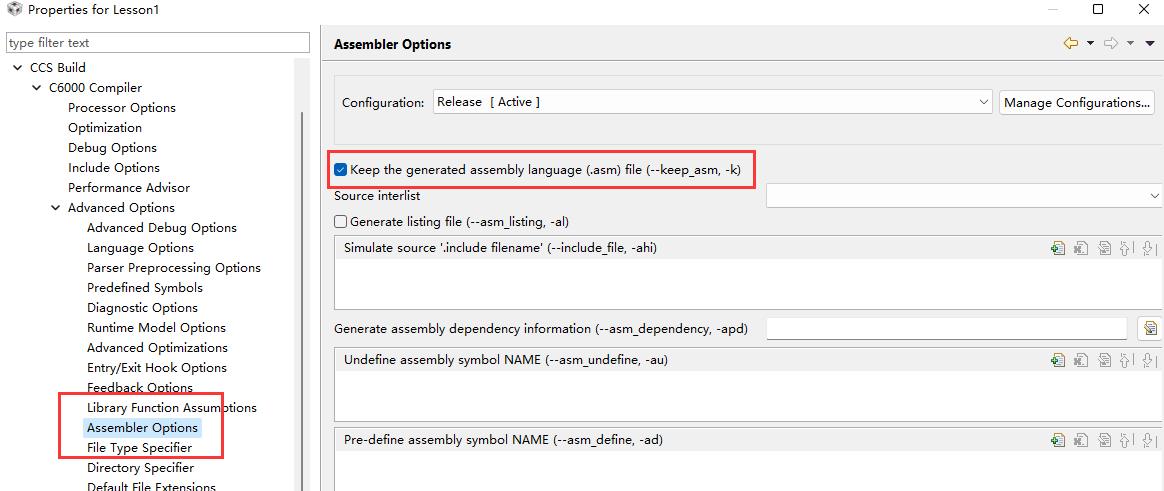
在工程选项中勾选上-mw和-k,那样可以在编译后生成汇编文件并且有软件流水线相关的信息,便于后续分析。
Lesson1 - 循环内部依赖
以两个向量的线性乘加运算为例:
sum=i∑ω1xi+ω2yi
源操作数都是short类型,向量长度为N,可以用C语言写出下面这个函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| void lesson(short * xptr, short * yptr, short *zptr, short *w_sum, int N)
{
int i, w_vec1, w_vec2;
short w1,w2;
w1 = zptr[0];
w2 = zptr[1];
for (i = 0; i < N; i++)
{
w_vec1 = xptr[i] * w1;
w_vec2 = yptr[i] * w2;
w_sum[i] = (w_vec1 + w_vec2) >> 15;
}
}
|
采用Release模式,开启O2优化,编译得到的汇编文件中有如下注释,里面包含了很多信息。Lesson1主要关注的是Loop Carried Dependency Bound这个条目。“Carry”有进位的含义,我对Loop Carried Dependency Bound的理解大概是:循环中的每一轮对前一轮的依赖,前一轮运行了多少个周期后能够开始新一轮的计算。
采用软件流水线的方式实现时,循环结构不再是顺序执行,循环中的每一轮计算一起构成流水线的结构。我们不需要等前一轮的计算完全结束就可以开始下一轮的计算,只要两者之间没有前后依赖关系。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| ;*----------------------------------------------------------------------------*
;* SOFTWARE PIPELINE INFORMATION
;*
;* Loop found in file : ../main.c
;* Loop source line : 24
;* Loop opening brace source line : 25
;* Loop closing brace source line : 29
;* Known Minimum Trip Count : 1
;* Known Max Trip Count Factor : 1
;* Loop Carried Dependency Bound(^) : 12
;* Unpartitioned Resource Bound : 2
;* Partitioned Resource Bound(*) : 2
;* Resource Partition:
;* A-side B-side
;* .L units 0 0
;* .S units 1 0
;* .D units 2* 1
;* .M units 1 0
;* .X cross paths 1 0
;* .T address paths 2* 1
;* Long read paths 0 0
;* Long write paths 0 0
;* Logical ops (.LS) 1 0 (.L or .S unit)
;* Addition ops (.LSD) 0 0 (.L or .S or .D unit)
;* Bound(.L .S .LS) 1 0
;* Bound(.L .S .D .LS .LSD) 2* 1
;*
;* Searching for software pipeline schedule at ...
;* ii = 12 Schedule found with 2 iterations in parallel
;*
;* Register Usage Table:
;* +-----------------------------------------------------------------+
;* |AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA|BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB|
;* |00000000001111111111222222222233|00000000001111111111222222222233|
;* |01234567890123456789012345678901|01234567890123456789012345678901|
;* |--------------------------------+--------------------------------|
;* 0: | * | *** |
;* 1: | * | *** |
;* 2: | * | *** |
;* 3: | * | *** |
;* 4: | * | *** |
;* 5: | ** | **** |
;* 6: | * | **** |
;* 7: | * | *** |
;* 8: | * | *** |
;* 9: | * | *** |
;* 10: | * | **** |
;* 11: | * | **** |
;* +-----------------------------------------------------------------+
;*
;* Done
;*
;* Loop will be splooped
;* Collapsed epilog stages : 0
;* Collapsed prolog stages : 0
;* Minimum required memory pad : 0 bytes
;*
;* Minimum safe trip count : 1
;* Min. prof. trip count (est.) : 13
;*
;* Mem bank conflicts/iter(est.) : { min 0.000, est 0.125, max 1.000 }
;* Mem bank perf. penalty (est.) : 1.0%
;*
;* Effective ii : { min 12.00, est 12.13, max 13.00 }
;*
;*
;* Total cycles (est.) : 12 + trip_cnt * 12
;*----------------------------------------------------------------------------*
;* SINGLE SCHEDULED ITERATION
;*
;* $C$C25:
;* 0 LDH .D2T2 *B7++,B4 ; |28| ^
;* || LDH .D1T1 *A4++,A3 ; |28| ^
;* 1 NOP 4
;* 5 PACK2 .L2X B4,A3,B4 ; |28| ^
;* 6 DOTP2 .M2 B4,B5,B4 ; |28| ^
;* 7 NOP 3
;* 10 SHR .S2 B4,15,B4 ; |28| ^
;* 11 STH .D2T2 B4,*B6++ ; |28| ^
;* || SPBR $C$C25
;* 12 NOP 9
;* 24 ; BRANCHCC OCCURS {$C$C25} ; |24|
;*----------------------------------------------------------------------------*
|
ii是iteration interval的简称,表示循环中每一轮计算的时间。可以看到Loop Carried Dependency Bound是12,而且ii也是12。这表明软件流水线根本没起作用,每一轮计算都得等上一轮计算结束才能开始。
Loop Carried Dependency Bound后面有一个“^”的符号,在最后的汇编代码中也可以看到,这是编译器帮我们标注出来的“关键路径”,表明执行这些汇编指令的时候形成了前后依赖关系。
我们其实自己知道向量中的每一个元素的计算都是相互独立地,并不存在前后地依赖关系。但编译器不知道这点,它看到有两个指针在先后读写存储器,就会采取一种保守地策略,认为需要写指针完成写操作后才能通过读指针读存储器。
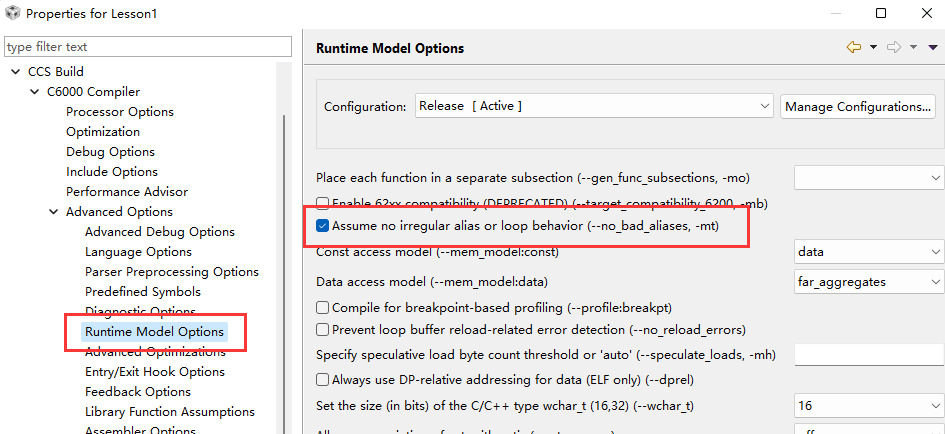
有两种方式可以告诉编译器这一额外的信息。一、用restrict限定指针;二、编译时加上“-mt”的编译选项。
在指针变量声明的时候加上restrict限定可以告诉编译器这个指针访问的数据只有它能够访问,其它指针的数据读写和它无关。
1
| void lesson(short * restrict xptr, short * restrict yptr, short *zptr, short *w_sum, int N)
|
“-mt”的选项能够假设没有那种两个指针访问同一片存储区的情况。
DSP进行计算的过程中,Load和Store是非常费时间的,Load完成需要5个周期,Store完成需要4个周期。在很多情况下,往往就是Load和Store形成了计算速度的瓶颈,所以在用指针的时候需要特别注意这种情况。
给指针添加“restrict”限定后的软件流水线信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| ;*----------------------------------------------------------------------------*
;* SOFTWARE PIPELINE INFORMATION
;*
;* Loop found in file : ../main.c
;* Loop source line : 24
;* Loop opening brace source line : 25
;* Loop closing brace source line : 29
;* Known Minimum Trip Count : 1
;* Known Max Trip Count Factor : 1
;* Loop Carried Dependency Bound(^) : 0
;* Unpartitioned Resource Bound : 2
;* Partitioned Resource Bound(*) : 2
;* Resource Partition:
;* A-side B-side
;* .L units 0 0
;* .S units 0 1
;* .D units 1 2*
;* .M units 0 1
;* .X cross paths 0 1
;* .T address paths 1 2*
;* Long read paths 0 0
;* Long write paths 0 0
;* Logical ops (.LS) 0 1 (.L or .S unit)
;* Addition ops (.LSD) 0 0 (.L or .S or .D unit)
;* Bound(.L .S .LS) 0 1
;* Bound(.L .S .D .LS .LSD) 1 2*
;*
;* Searching for software pipeline schedule at ...
;* ii = 2 Schedule found with 6 iterations in parallel
;*
;* Register Usage Table:
;* +-----------------------------------------------------------------+
;* |AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA|BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB|
;* |00000000001111111111222222222233|00000000001111111111222222222233|
;* |01234567890123456789012345678901|01234567890123456789012345678901|
;* |--------------------------------+--------------------------------|
;* 0: | * | ***** |
;* 1: | ** | ***** |
;* +-----------------------------------------------------------------+
;*
;* Done
;*
;* Loop will be splooped
;* Collapsed epilog stages : 0
;* Collapsed prolog stages : 0
;* Minimum required memory pad : 0 bytes
;*
;* Minimum safe trip count : 1
;* Min. prof. trip count (est.) : 2
;*
;* Mem bank conflicts/iter(est.) : { min 0.000, est 0.125, max 1.000 }
;* Mem bank perf. penalty (est.) : 5.9%
;*
;* Effective ii : { min 2.00, est 2.13, max 3.00 }
;*
;*
;* Total cycles (est.) : 10 + trip_cnt * 2
;*----------------------------------------------------------------------------*
;* SINGLE SCHEDULED ITERATION
;*
;* $C$C22:
;* 0 LDH .D2T2 *B6++,B8 ; |28|
;* || LDH .D1T1 *A4++,A3 ; |28|
;* 1 NOP 4
;* 5 PACK2 .L2X B8,A3,B8 ; |28|
;* 6 DOTP2 .M2 B8,B5,B4 ; |28|
;* 7 NOP 3
;* 10 SHR .S2 B4,15,B4 ; |28|
;* 11 STH .D2T2 B4,*B7++ ; |28|
;* || SPBR $C$C22
;* 12 ; BRANCHCC OCCURS {$C$C22} ; |24|
;*----------------------------------------------------------------------------*
|
可以看到添加了“restrict”限定之后,Loop Carried Dependency Bound变为0,前后两轮计算之间不再有依赖关系,ii从12降低到了2,运算效率大幅度提高!
Lesson2 - 平衡两条数据路径
观察前面优化后的Resource Partition,可以看到AB两条数据路径的使用并不对称。B中的功能单元用得更多,而A中的功能单元大部分是空闲的。
这里可以用到循环展开(Loop Unroll)的技术。一般情况下循环N次,那么这个循环的trip count就是N。而有时候可以把相邻的两轮计算当作一次trip,那么这个循环的trip count就是N/2。DSP软件在用软件流水线优化以后,循环的次数就是用trip count来衡量的。
编译器不会自动地展开循环,只有在知道某个循环必定会执行N次或者执行的次数必定为某个数的整数倍时才会尝试展开循环。
1
| #pragma MUST_ITRATE(min, max, multiple);
|
用MUST_ITERATE可以说明一个循环的最小循环次数min、最大循环次数max和循环次数的整数因子。比如
1
| #pragma MUST_ITERATE(2, , 2);
|
可以告诉编译器下面的for循环最小执行2次,而且执行次数是2的整数倍。把这行代码应用到前面的例子里就像下面这样:
1
2
3
4
5
6
7
| #pragma MUST_ITERATE(2, , 2);
for (i = 0; i < N; i++)
{
w_vec1 = xptr[i] * w1;
w_vec2 = yptr[i] * w2;
w_sum[i] = (w_vec1 + w_vec2) >> 15;
}
|
重新编译得到如下结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| ;*----------------------------------------------------------------------------*
;* SOFTWARE PIPELINE INFORMATION
;*
;* Loop found in file : ../main.c
;* Loop source line : 25
;* Loop opening brace source line : 26
;* Loop closing brace source line : 30
;* Loop Unroll Multiple : 2x
;* Known Minimum Trip Count : 1
;* Known Max Trip Count Factor : 1
;* Loop Carried Dependency Bound(^) : 0
;* Unpartitioned Resource Bound : 2
;* Partitioned Resource Bound(*) : 3
;* Resource Partition:
;* A-side B-side
;* .L units 0 0
;* .S units 1 1
;* .D units 2 2
;* .M units 0 2
;* .X cross paths 1 1
;* .T address paths 3* 3*
;* Long read paths 0 0
;* Long write paths 0 0
;* Logical ops (.LS) 1 2 (.L or .S unit)
;* Addition ops (.LSD) 0 0 (.L or .S or .D unit)
;* Bound(.L .S .LS) 1 2
;* Bound(.L .S .D .LS .LSD) 2 2
;*
;* Searching for software pipeline schedule at ...
;* ii = 3 Schedule found with 5 iterations in parallel
;*
;* Register Usage Table:
;* +-----------------------------------------------------------------+
;* |AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA|BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB|
;* |00000000001111111111222222222233|00000000001111111111222222222233|
;* |01234567890123456789012345678901|01234567890123456789012345678901|
;* |--------------------------------+--------------------------------|
;* 0: | **** | ** *** * |
;* 1: | **** | ****** * |
;* 2: | **** | **** * * |
;* +-----------------------------------------------------------------+
;*
;* Done
;*
;* Loop will be splooped
;* Collapsed epilog stages : 0
;* Collapsed prolog stages : 0
;* Minimum required memory pad : 0 bytes
;*
;* Minimum safe trip count : 1 (after unrolling)
;* Min. prof. trip count (est.) : 2 (after unrolling)
;*
;* Mem bank conflicts/iter(est.) : { min 1.000, est 1.000, max 1.000 }
;* Mem bank perf. penalty (est.) : 25.0%
;*
;* Effective ii : 4.0
;*
;*
;* Total cycles (est.) : 12 + trip_cnt * 3
;*----------------------------------------------------------------------------*
;* SETUP CODE
;*
;* MV A6,B9
;* ADD 6,B9,B9
;* ADD 4,A6,A6
;*
;* SINGLE SCHEDULED ITERATION
;*
;* $C$C23:
;* 0 LDNW .D1T1 *A3++(4),A5 ; |29|
;* 1 LDNW .D2T2 *B7++(4),B4 ; |29|
;* 2 NOP 3
;* 5 UNPKH2 .L1 A5,A5:A4 ; |29|
;* 6 UNPKH2 .L2 B4,B5:B4 ; |29|
;* 7 DPACKL2 .L2X B5:B4,A5:A4,B5:B4 ; |29|
;* 8 DOTP2 .M2 B4,B16,B8 ; |29|
;* 9 DOTP2 .M2 B5,B16,B6 ; |29|
;* 10 NOP 3
;* 13 SHR .S1X B8,15,A4 ; |29|
;* || SHR .S2 B6,15,B6 ; |29|
;* 14 STH .D1T1 A4,*A6++(4) ; |29|
;* || STH .D2T2 B6,*B9++(4) ; |29|
;* || SPBR $C$C23
;* 15 ; BRANCHCC OCCURS {$C$C23} ; |25|
;*----------------------------------------------------------------------------*
|
ii从2变为了3,实际上是经过了循环展开,新的代码中trip count减小了一半。所以实际上可以理解为ii从2变为了1.5,计算效率进一步得到提升。
Lesson3 - 地址对齐
再仔细观察上面的软件流水线信息,.T address path总共用了6次。因为两次取操作数和写回计算结果是3次,又经过了循环展开,所以总共是6次。
但实际上我们的操作数都是short类型的,如果把两个连续的操作数一起load,那么可以将.T adrress path的使用次数降低到4次。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| void lesson(short * restrict xptr, short * restrict yptr, short *zptr, short *w_sum, int N)
{
int i, w_vec1, w_vec2;
short w1,w2;
_nassert(((int)xptr & 0x3) == 0);
_nassert(((int)yptr & 0x3) == 0);
w1 = zptr[0];
w2 = zptr[1];
#pragma MUST_ITERATE(2, , 2);
for (i = 0; i < N; i++)
{
w_vec1 = xptr[i] * w1;
w_vec2 = yptr[i] * w2;
w_sum[i] = (w_vec1 + w_vec2) >> 15;
}
}
|
新增加的_nassert语句不会生成额外的代码,但可以告诉编译器更多的信息。_nassert()后的括号内的表达式为真。增加了新的约束后就告诉了编译器xptr和yptr是8字节对齐的,可以用LDW直接load两个short类型的数据,如果没有这个信息,编译器只会用LDNW指令来load非对齐的32bit数据,相对来说会慢一点。
编译后的软件流水线信息如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| ;*----------------------------------------------------------------------------*
;* SOFTWARE PIPELINE INFORMATION
;*
;* Loop found in file : ../main.c
;* Loop source line : 29
;* Loop opening brace source line : 30
;* Loop closing brace source line : 34
;* Loop Unroll Multiple : 2x
;* Known Minimum Trip Count : 1
;* Known Max Trip Count Factor : 1
;* Loop Carried Dependency Bound(^) : 0
;* Unpartitioned Resource Bound : 2
;* Partitioned Resource Bound(*) : 2
;* Resource Partition:
;* A-side B-side
;* .L units 0 0
;* .S units 1 1
;* .D units 2* 2*
;* .M units 0 2*
;* .X cross paths 1 1
;* .T address paths 2* 2*
;* Long read paths 0 0
;* Long write paths 0 0
;* Logical ops (.LS) 1 2 (.L or .S unit)
;* Addition ops (.LSD) 0 0 (.L or .S or .D unit)
;* Bound(.L .S .LS) 1 2*
;* Bound(.L .S .D .LS .LSD) 2* 2*
;*
;* Searching for software pipeline schedule at ...
;* ii = 2 Schedule found with 8 iterations in parallel
;*
;* Register Usage Table:
;* +-----------------------------------------------------------------+
;* |AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA|BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB|
;* |00000000001111111111222222222233|00000000001111111111222222222233|
;* |01234567890123456789012345678901|01234567890123456789012345678901|
;* |--------------------------------+--------------------------------|
;* 0: | ***** | ****** ** |
;* 1: | ****** | ****** ** |
;* +-----------------------------------------------------------------+
;*
;* Done
;*
;* Loop will be splooped
;* Collapsed epilog stages : 0
;* Collapsed prolog stages : 0
;* Minimum required memory pad : 0 bytes
;*
;* Minimum safe trip count : 1 (after unrolling)
;* Min. prof. trip count (est.) : 2 (after unrolling)
;*
;* Mem bank conflicts/iter(est.) : { min 1.000, est 1.125, max 2.000 }
;* Mem bank perf. penalty (est.) : 36.0%
;*
;* Effective ii : { min 3.00, est 3.13, max 4.00 }
;*
;*
;* Total cycles (est.) : 14 + trip_cnt * 2
;*----------------------------------------------------------------------------*
;* SETUP CODE
;*
;* MV A7,B16
;* ADD 6,B16,B16
;* ADD 4,A7,A7
;*
;* SINGLE SCHEDULED ITERATION
;*
;* $C$C22:
;* 0 LDW .D1T1 *A6++,A3 ; |33|
;* 1 NOP 1
;* 2 LDW .D2T2 *B8++,B5 ; |33|
;* 3 NOP 3
;* 6 UNPKH2 .L1 A3,A5:A4 ; |33|
;* 7 UNPKH2 .L2 B5,B5:B4 ; |33|
;* 8 DPACKL2 .L2X B5:B4,A5:A4,B7:B6 ; |33|
;* 9 DOTP2 .M2 B6,B17,B9 ; |33|
;* 10 DOTP2 .M2 B7,B17,B6 ; |33|
;* 11 NOP 3
;* 14 SHR .S1X B9,15,A8 ; |33|
;* || SHR .S2 B6,15,B4 ; |33|
;* 15 STH .D1T1 A8,*A7++(4) ; |33|
;* || STH .D2T2 B4,*B16++(4) ; |33|
;* || SPBR $C$C22
;* 16 ; BRANCHCC OCCURS {$C$C22} ; |29|
;*----------------------------------------------------------------------------*
|
可以看到新的ii已经相当于是从1.5降低到了1,计算效率进一步提高。
Lesson4 - 程序级优化
编译器编译过程中只能看到某个函数作用域内的信息,再工程选项中勾选程序级优化(-pm)有时候也能实现前面的优化效果。
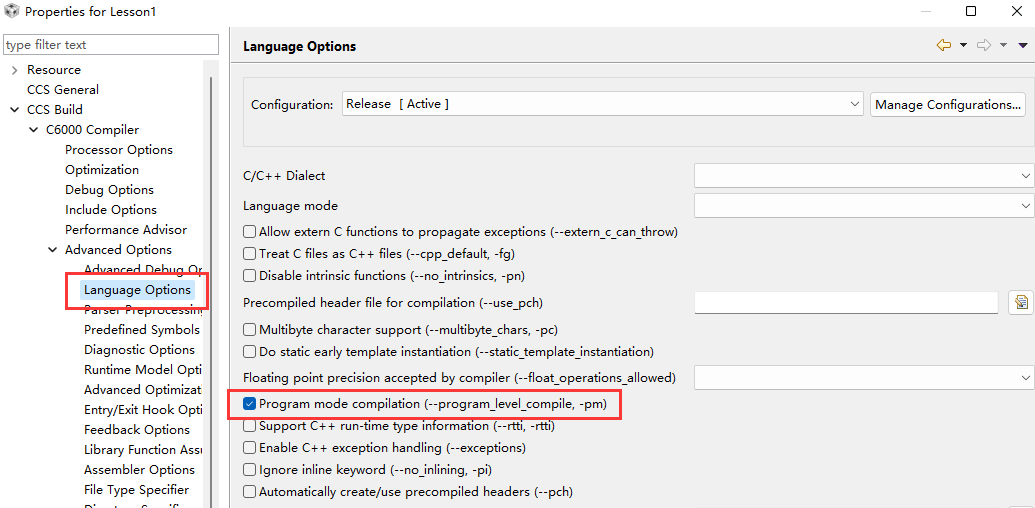
Lesson5 - 线性汇编
写线性汇编我觉得是最后没办法的办法了,用汇编指令顺序地将计算过程写下来,编译器再对这些汇编指令进行并行、流水线的处理。我也不知道这样能提升多少,感觉会是费力不讨好的事情。可能写了半天线性汇编,最后提升的也就只有一点点。挖个坑,等之后如果我遇到了这种需求,再写一下这部分内容把。