用于多核DSP开发的核间通信
TI的多核DSP以TMS320C6678为例,它是多核同构的处理器,内部是8个相同的C66x CorePac。对其中任意一个核的开发就和单核DSP开发的流程是类似的。
但是如果仅仅只是每个核独立开发,那么很难体现出多核的优势。要充分发挥多核处理器的性能,势必需要涉及核间通信,另外还有许多共享资源的分配的问题需要考虑。
IPC(Inter-Processor Communication)是RTSC体系下的一个Package,专门用来实现不同核之间的通信。IPC可以在这里下载。3.0版本以后的IPC会直接包含在对应的SDK里面,如果要用更早的版本,也可以再下载,只是要注意最好对上XDCTools和SYS/BIOS的版本。
| IPC 版本 | 3.50.04 | 1.25.03 |
|---|---|---|
| XDCTools | 3.55.02 | 3.24.05 |
| SYS/BIOS | 6.76.03 | 6.34.04 |
3.50版本的IPC是包含在C667x的PDK里的,但我在安装的时候XDCTools安装失败了,可能是CCS版本比较老的原因,所以我就用的是1.25版本的IPC。虽然这两个版本号有很大差别,但是用起来应该差不多吧,我猜。这个Package的使用主要就看文档就好了,我在这里只做一些简短的记录。
IPC Package里有很多module,要使用这些module,需要include的头文件在<ipc_install_dir>/packages/ti/ipc/目录下面,一般都会用到这些:
1 | // type define |
不管是用Linux内核还是用SYS/BIOS内核,用到的都是这些头文件。在include这些头文件之前要另外include一个关于类型定义的头文件<xdc/std.h>。关于这些头文件里的API的说明在<ipc_install_dir>/docs/doxygen/html/index.html里有,是用doxygen根据源码里的注释生成的文档。
由XDCTools编译生成的<ipc_install_dir>/packages/ti/sdo/ipc/目录下的头文件是不能直接使用的。这些module可以在.cfg配置文件中进行配置,在C/C++源文件中只需要看上面的头文件里提供的API就可以了。
核间通信的初始化
核间通信的初始化会用到三个module,分别是Ipc,MultiProc和SharedRegion。Ipc模块可以用ProcSync_ALL属性来设置成自动同步每个核,这样在执行完Ipc_start()之后,每个核之间就同步完成了,不需要手动去调用Ipc_attach()。有时候我们不需要每个核之间都同步时就可以去手动调用Ipc_attach(),让特定的几个核之间建立联系。
Ipc_attach()要成功,还需要用到MultiProc模块,它可以设置我们的多核程序需要用到那几个核,当前这个工程是针对哪个核来编写的,例如下面我准备用4个核,然后当前的配置是针对核0来编写的。核0执行Ipc_start()的时候就会尝试去和另外三个核建立联系。
核间同步需要用到一块共享的数据区,因此需要用到SharedRegion,SharedRegion0会被用来做这些事,大概会需要用几百个字节吧,剩下的空间用户仍然可以继续使用。
1 | var Ipc = xdc.useModule('ti.sdo.ipc.Ipc'); |
上面是一个配置的示例,在这之前,每个核的platform一定要有一块相同物理地址的共享存储区。如果它们在不同核中的逻辑地址不同,那么需要SharedRegion.translate设置成true,进行地址转换。我在MSMC中选择512kB用作SharedRegion0,它在每个核中的地址都是相同的所以可以设置成false,节省资源。SharedRegion的cacheLineSize需要根据实际情况设置,MSMC会被L1D cache,查阅文档可以指导L1D cache的cacheline是64字节。
1 | // IPC initialization |
配置完成后,在每个核的main函数中最开始的位置执行Ipc_start(),不出意外每个核之间会完成同步,之后就可以执行其它的IPC模块的API。可以在调试程序,然后通过ROV查看Ipc模块的状态,下图是核0与其它三个核的同步的情况,attached都是true表明核0已经与其它三个和都同步上了。

Notify
Notify适合用来发送简短的信息,因为Notify可以带一个32bit的payload。Notify通信的基础是IPC寄存器,C6678的IPC寄存器中只有4-31共28个事件源。某个核如果想要收到另一个核的Notify,就需要先注册这个Notify,将某个事件源和一个回调函数(callback)绑定。
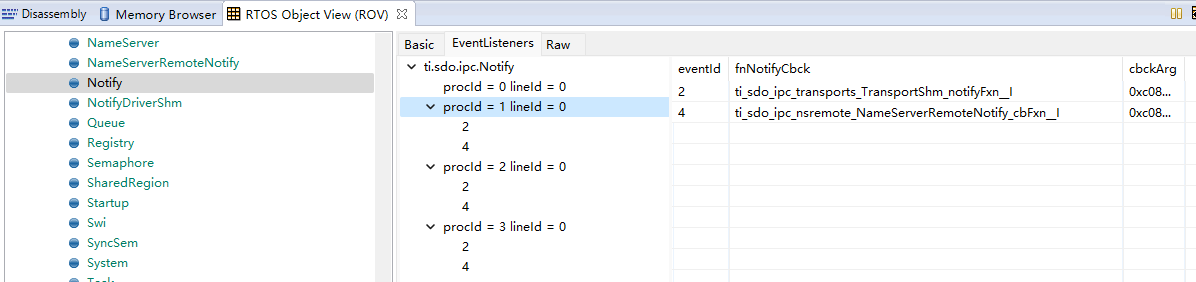
我没有为核0注册Notify事件,但是它本身就已经有了两个事件Id被注册了。所以用的时候要注意,不要用2号和4号EventId,会产生冲突。用5-31号的EventId应该没问题。提到这个我还想到,DSP的CorePac里4-15的中断Id里,5号中断已经被用来处理IPC中断了,14号中断用来处理定时器中断,因此这两个中断号也是不能用的。
MessageQ
Notify能够发送的数据有限,但如果只是发送一个数据块,Notify也可以只发送一个数据块的首地址指针。MessageQ可以用来发送批量的数据,而且可以很方便地与任务调度结合起来。比如一个Task如果需要等待另一个核产生的数据,如果用Notify实现,那么需要在Notify的Callback函数里产生一个Semaphore,在Task里等待这个Semaphore。而MessageQ则可以只通过MessageQ_get()函数实现接收数据和Semaphore等待的功能。MessageQ相比于Notify更大的优势在于它是一个队列,可以对收到的消息按照优先级排队,处理器可以依次处理每个消息。
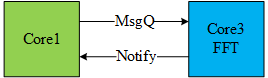
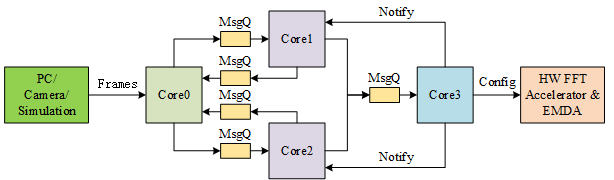
通过MessageQ发送的Message的长度可以是任意的,我们可以根据自己的需求定义数据结构。比如我最近用Core1调用Core3执行FFT,FFT计算完成后Core3通过Notify告知Core1计算完成。那么Core1就需要利用MessageQ将一些必要的参数告诉Core3。因此我定义了以下的数据结构FftMsg,其中包括FFT计算的类型、源数据地址、目的数据地址、二维FFT的长和宽。只要保证这个数据结构最前面是MessageQ_MsgHeader,后面可以随意。header里面本身是由一个replyQueueId的,可以方便接收方将Message返回给发送方。header里面还有一个MessageId,用来区分发往同一个MessageQ的不同类型的Message。我自己又加了一个nReplyCoreId,用来告诉Core3在FFT计算完成后,要向哪个Core发送Notify。
1 | typedef enum FFT2dType |
MessageQ是由接收方创建的,Core1要往Core3发送Message,Core1只需要打开Core3创建的MessageQ即可。有可能会打开失败,因为Core3可能一开始还没创建好这个MessageQ,所以做了一个do-while循环。
Core1在调用之前一定要确保源数据都已经写回共享的存储区,如果还留在Core1本地的Cache里,那么计算结果就会出错。
要发送的Message是动态分配的,一般是动态分配在一个SharedRegion里构建的堆区,每个核都需要为同一个堆区注册一个相同的HeapId,MessageQ_alloc靠HeapId来决定在哪里动态分配数据空间。
Mesage可以设置优先级,优先级只有三种,默认是Normal,较高的是MessageQ_HIGHPRI,最高优先级是MessageQ_URGENTPRI。
1 | // Core1 code, FFT caller |
Core3是接收方,首先需要创建一个MessageQ来接收Message。然后就可以不停等待Message,就像作为一个服务器不断处理客户端发过来的计算任务。
1 | // Core3 code, FFT callee |
GateMP
GateMP用来让多核互斥访问某些资源,这个我暂时还没用到,但用起来也挺简单的,文档上也都写得很清楚。