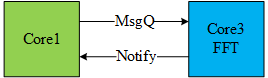基于多核DSP的双目标KCF跟踪实现
KCF目标跟踪算法在DSP上实现的具体细节我已写了一篇文章,已被《红外技术》期刊录用,应该不久之后会见刊。文中主要介绍如何用单核DSP和硬件FFT加速器实现KCF算法,并满足实时性需求。
后来为了用KCF跟踪算法同时跟踪两个不同的目标,就有了这篇文章所介绍的工作,本文主要就是分享一下我的设计过程,同时也作为一个多核DSP工程的示例(Gitee链接)。多核工程在实现的过程中主要要解决的就是不同核之间的同步的问题和共享资源的互斥访问的问题。
软件整体结构
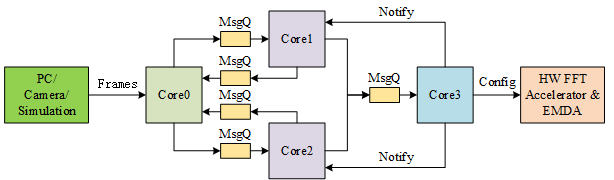
多核程序的设计首先可以确定软件的整体结构,可以是主从式,也可以是流水线的形式。最好能平衡每个核的工作量,合理地安排每个核的任务。我这次采用的是类似主从式的结构,软件整体框图如上图所示。主要实现以下功能:
- Core0负责接收图像数据,采用乒乓缓存的方式接收,在处理当前帧的同时可以同时接收新的数据。Core0可以按照一定的帧频接收图像,也可以主动向PC发出接收图像的请求。
- Core0通过消息队列(MsgQ)向Core1和Core2发送命令,执行KCF跟踪算法,Core1和Core2分别将两个目标框的左上角坐标和长宽(x,y,w,h)通过MsgQ返回Core0,由Core0汇总结果;
- Core1和Core2在计算过程中需要调用硬件FFT加速器,Core3作为中介,Core1和Core2只需要将FFT计算的需求通过MsgQ发送给Core3即可;
- Core3按照收到的计算需求配置硬件FFT加速器和EDMA来完成二维FFT计算。并在完成计算后利用Notify告知相应的核。Core1和Core2可以在指定的地址直接获得计算结果。
存储空间分配
嵌入式系统往往都存在资源有限的问题,在确定每个核大致的任务之后,就应该根据每个核的需求来划分一些共享的存储空间。
存储空间
TMS320C6678或者是银河飞腾FT-M6678的存储空间分配情况如下表所示。我们主要关注的是L2的配置以及MSMC SRAM和DDR3的空间划分。
| 类别 | 大小 | 备注 |
|---|---|---|
| L1D | 32kB (per core) | 一般都作为Cache使用 |
| L1P | 32kB (per core) | 一般都作为Cache使用 |
| L2 | 512kB (per core) | 可以部分作为Cache,用于缓存DDR3中的数据或指令;或者作为SRAM |
| MSMC SRAM | 4MB (shared) | 由多核共享存储器控制器(Multicore Shared Memory Controller)管理的SRAM,由8个核共享,访问速度类似于L2 |
| DDR3 | 2GB (shared) | DDR3的访问速度相比于L2或者MSMC SRAM的访问速度要慢得多,为了保证计算的实时性,如果用DDR3存放数据,一定要将部分L2作为Cache使用 |
存储配置
存储器的使用情况如下表所示。数据区能放在MSMC SRAM就放,迫不得已才放到DDR上去,因为如果把数据放在DDR上,计算起来真的非常慢,即使是用了L2 Cache,也不如直接把数据放在MSMC SRAM上快。代码的量一般比较少,每个核的L2基本够用。
| Core | L2 Cache | L2 SRAM | MSMC SRAM | DDR3 |
|---|---|---|---|---|
| Core0 | 256kB | 256kB Code Memory | 256kB Data Memory | 128MB (images for simulation) |
| Core1 | 128kB | 384kB Code Memory | 1.5MB Data Memory | 128MB |
| Core2 | 128kB | 384kB Code Memory | 1.5MB Data Memory | 128MB |
| Core3 | 256kB | 256kB Code Memory | 256kB Data Memory | 128MB |
| Shared | / | / | 512kB SharedRegion0 | 1GB SharedRegion1 |
| Total/Rate | / | / | 4MB/100% | 1.5GB/75% |
在此之前我已经完成了单核实现KCF算法的功能,当时的计算在堆区开辟了1MB以上的空间,因此我为Core1和Core2各分配了1.5MB的MSMC SRAM来满足KCF计算的需求。之前也试过直接放在DDR上,但是计算速度不理想。
我为每个核分配的128MB的DDR上的空间基本都是没用的,除了Core0用来存放仿真用的图像数据。因此他们的L2 Cache的大小其实无所谓,MSMC SRAM上的数据是直接缓存到L1上去的,不会用到L2 Cache。而KCF计算的代码量也超过了256kB,因此我为Core1和Core2各分配了384kB用作代码区。
从MSMC SRAM中取512kB作为共享数据区,配置为SharedRegion0,用于IPC模块的核间通信。在DDR中划出1GB的共享存储空间,配置为SharedRegion1,用于在核间传输大批量的数据。比如Core0的红外图像乒乓接收,一张图是320kB,因此接收缓冲区需要640kB。SharedRegion0的访问速度快,但是大小不够,因此这一接收缓冲区需要设置在SharedRegion1里,Core1和Core2都通过这一共享数据区来获取待处理的红外图像。
测试流程
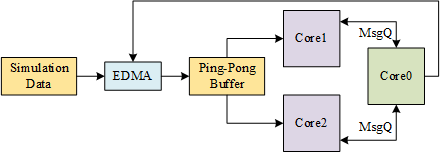
目前只进行了仿真测试,用于测试的图像数据事先加载到DDR中,由Core0配置EDMA,将图像搬运到同样位于DDR的乒乓接收缓冲区,而后由Core1和Core2完成两个目标的KCF跟踪运算,并将结每一帧的结果通过消息队列返回Core0。
利用调试器向DDR加载图像数据非常慢,因此我们只采用了10张图片进行测试,在此之前已在单核上运行,结果如下图:
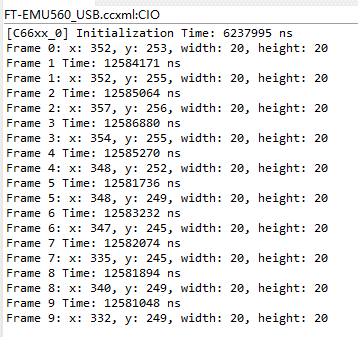
将单核运行结果作为参考标准,对于双目标跟踪的测试采用同样的目标,运行结果与单核一致则跟踪正确。也可以看到,除了第一帧图像外,单核处理每帧图像所需的时间为12.6ms左右。
任务调度
根据我们的设想,我们在Core0上设置了三个任务,优先级从高到低依次是MainTask,C1KcfTask和C2KcfTask。MainTask负责启动EDMA来模拟仿真图像数据的接收。虽然我们实际用了10张图像序列进行测试,但太多了画不下,所以这里只画了处理两张图的示意图。
程序启动后,由MainTask首先启动接收一张图像,图像接收完成时,C1KcfTask和C2KcfTask都会收到信号,并依次启动Core1和Core2开始执行KCF算法。当两个核都开始处理图像时,MainTask再次启动接收下一帧图像。
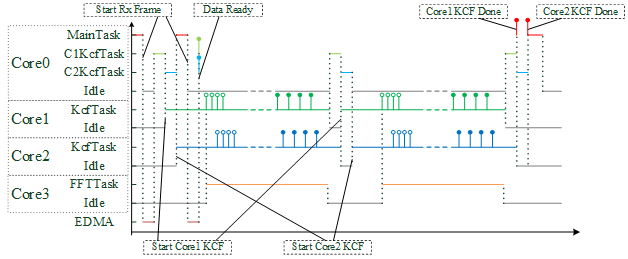
当Core1和Core2完成计算时,C1KcfTask和C2KcfTask知道下一帧图像已经接收完成,因此它们紧接着又让Core1和Core2开始下一帧的计算。当两帧图像均处理完后,C1KcfTask和C2KcfTask向MainTask报告测试实验结束,结束整个测试过程。
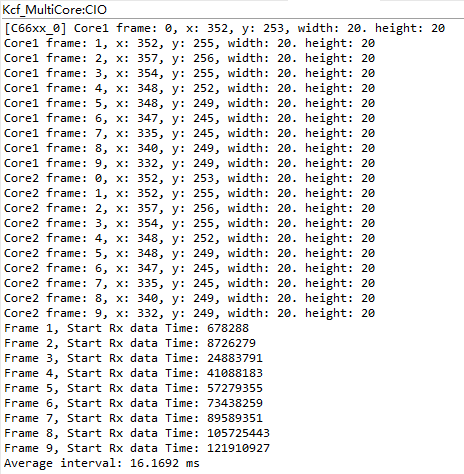
上图的实验结果中,两个核跟踪的目标框位置与单核运行结果一致。我们记录了每次MainTask启动接收图像的时刻,除去第一帧图像处理所用的时间,其余时间间隔的平均值为16.2ms。两个核在运算的过程中都要用到硬件FFT加速器和EDMA,虽然已经用Core3单独管理这部分共享的硬件外设,保证了计算的正确性,但这种集中的调用还可能会造成数据传输上的瓶颈导致运算效率下降。
优先队列
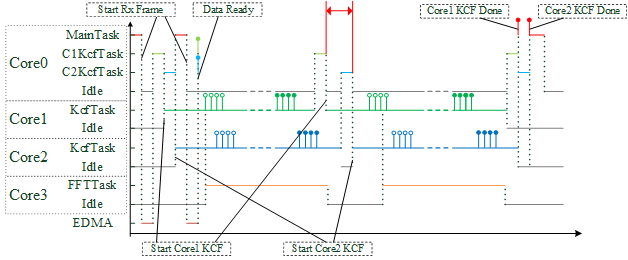
为了解决前面的问题,我们将Core3的FFT命令队列引入优先级的机制,Core1调用FFT的优先级更高,Core2的优先级次之,这样我们能保证尽快完成Core1的计算。启动Core1和Core2的时刻也会自然地错开,这也是我们为什么在Core0里单独设计了两个任务C1KcfTask和C2KcfTask的原因,因为这样就能够更容易地分别控制Core1和Core2的启动时刻。
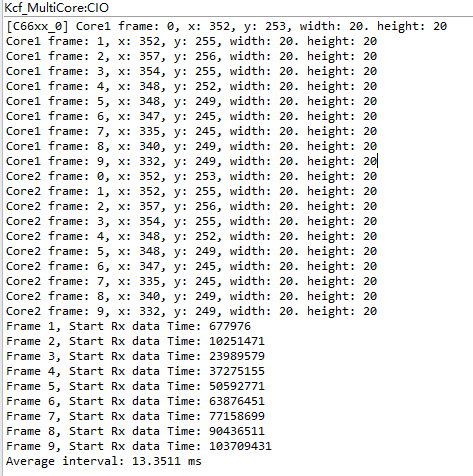
在FFT命令队列中引入优先级机制后,对比前后两次测试的结果,可以看到处理第一帧图像的时间略微增加了,猜测可能是根据优先级排队产生的额外开销,但后续的几帧图像的处理时间明显缩短,最终单帧图像的处理时间仅需13.4ms左右。