输入输出延时的时序约束
关于FPGA设计时的输入延时、输出延时的基本概念,网上已经有很多文章进行了介绍。
文章链接:FPGA静态时序分析
我主要也是通过上面这篇文章进行学习的。但是文章中对于最大输入延时的推导有一点小错误,而且整体上看比较复杂,为此本文进行了适当总结。
在很多文章的分析中,常常引入时钟抖动(jitter),时钟偏斜(skew),因此常常会显得比较复杂。为了便于分析,时钟的这部分不确定性我们可以暂时不考虑,即把发射(launch)和捕获(capture)的时钟看作完全相同的时钟。
建立时间与保持时间
在讨论输入输出延时之前,一定要对建立时间和保持时间有足够的理解。
建立时间是否满足,需要考虑发射沿和捕获沿之间的关系,是前后两个时钟沿。从发射沿开始,经过一定的延时,数据在捕获端稳定。在捕获沿到来前,数据至少要稳定一定的时间,这一段时间称为建立时间。
保持时间是否满足可以仅考虑捕获沿,即同一个时钟沿。捕获端在捕获数据时,数据需要保持一段时间,而有可能因为发射端数据来得太快导致保持时间不满足。
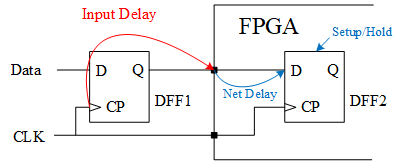
输入延时
输入延时即图中红色弧线表示,DFF1的时钟端到FPGA的PAD的时间 ...
基于PCIe的FPGA与DSP间高速数据传输测试
DSP端的PCIe外设使用
PCIe接口在FPGA上的实现
结合我前面两篇文章对FPGA和DSP两边的实现,本文对整个测试结果做一个总结。我用的FPGA和DSP都是国产的,对标Xilinx的XC7VX690T FPGA和TI的TMS320C6678 DSP。DSP作为RC,FPGA作为EP,实现DSP通过PCIe接口读写FPGA外接的DDR。
FPGA接口写时序图
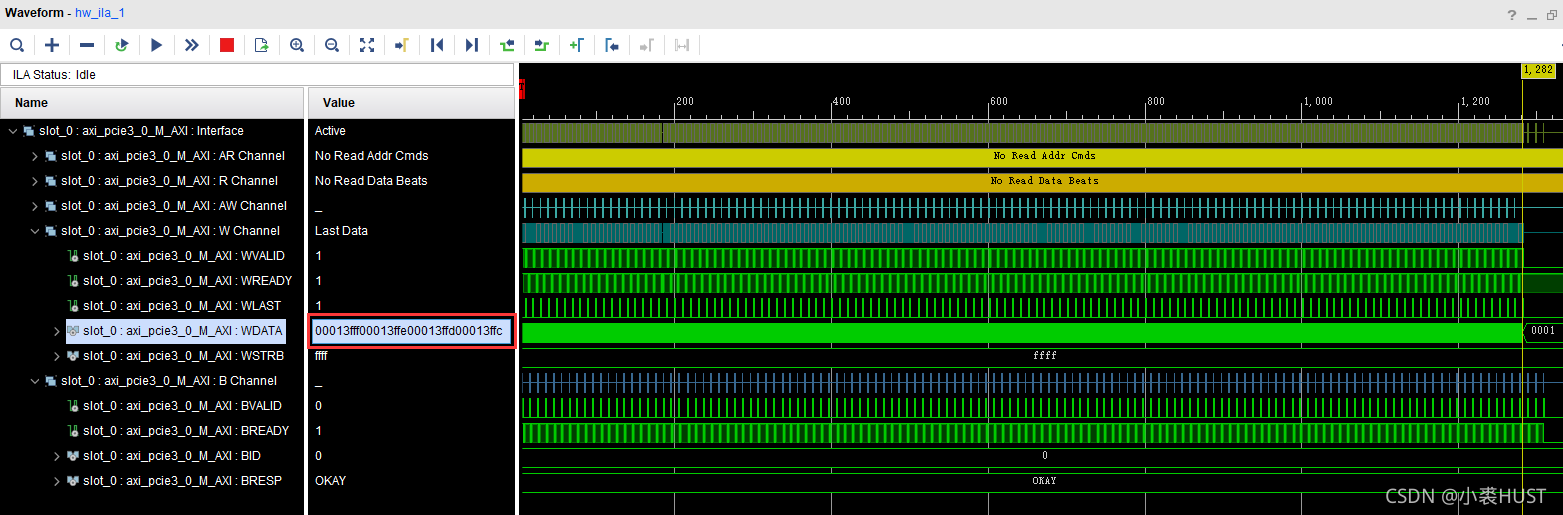
总共的数据量是640×512×8bit,是一帧图像的大小。具体的数据是我生成的,不是真正的图像数据。DSP端这些数据是以字的方式存储的,一共有81920个字节,换算成16进制就是0x14000。下面的图是在PCIe IP的AXI接口处抓到的波形,可以看到最后一个写进去的数据是0x13FFF,说明数据都写进去了。
下面的图是详细的写数据的波形,数据位宽是16字节,突发长度是8。在数据最终写入DDR之后,返回成功的写响应。
FPGA接口读时序图
下图是连续的读时序图,可以看到最后一个读出来的数据也是0x13FFF,所以读的数据也是没有问题的。
下面的图是详细的读数据的波形,可以看到在读地址的 ...
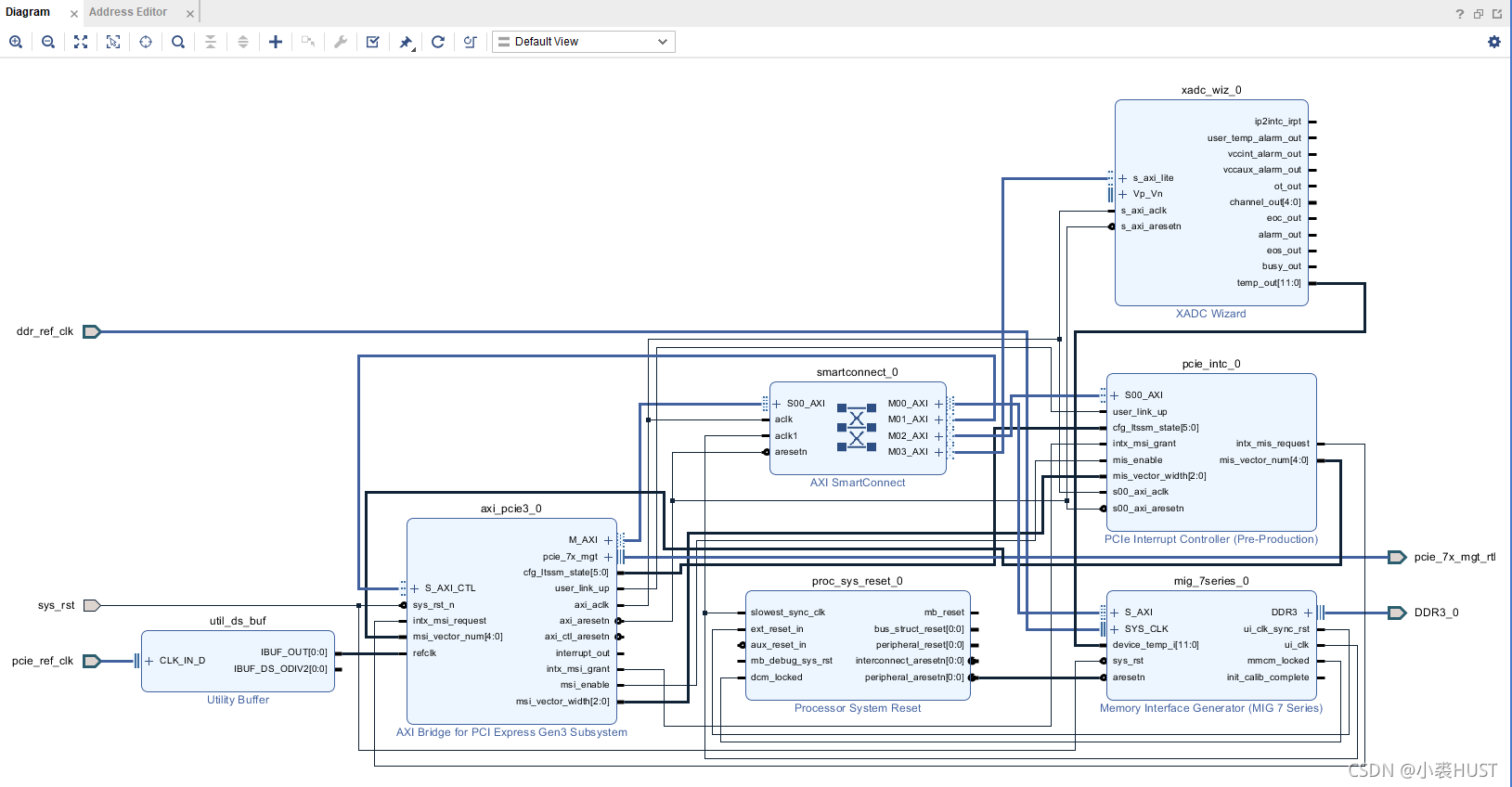
PCIe接口在FPGA上的实现
PCI Express Base Specification Revision 3.0
PCI Local Bus Specification Revision 3.0
书籍:PCI Express System Architecture,对应那本紫色的《PCI Express 体系结构标准教材》
上面的两个Specification的文档虽然不是从官网找的,但是可信度还是有保证的。我们学校图书馆有那本中文的书,基本上跟规范里的内容是一致的,而且应该更好理解一点。第一个规范里主要看第七章“Software Initialization and Configuration”,里面介绍了PCIe配置空间的大部分寄存器;第二个规范介绍的是PCI协议,PCIe很多都跟PCI兼容,所以这个文档也很重要,这里主要看第六章“Configuration Space”,MSI相关的寄存器只有在这个文档里才有。在开发过程中,Xilinx的IP文档里没有对这些配置寄存器做具体的说明,所以需要查看这两个规范文档。
目前我的需求是实现FPGA和DSP之间利用PCIe链路进行通信,所以准备先从FPGA ...

DSP端的PCIe外设使用
我用的DSP和TI的TMS320C6678类似,但是是国防科大的6678。它的PCIe外设和TI的有很大不同,但也实现了基本的功能。虽然文档不太详细,而且有些功能有点问题,但基本还是能用的。
链路初始化
6678的PCIe相关的地址空间是下面这样的,初始化阶段要做的工作就是对本地和远端的PCIe配置空间进行配置。6678作为RC,FPGA端作为EP,FPGA上的PCIe接口相关的寄存器就需要DSP来设置。寄存器的表需要查DSP的文档、FPGA的文档和PCIe协议规范的文档。具体寄存器的功能这里就不细说了。
链路初始化的第一步是初始化PCIe链路相关的时钟。这个只要按照DSP文档里写的方式初始化就行。
第二步是设置需要的链路数量和链路速率,链路数量是x4,然后速率是5.0GT/s。
12345678910#pragma CODE_SECTION (CSL_pcieRcConfig, ".text:csl_section:pcie");void CSL_pcieRcConfig(){ CSL_FINST(hPcieRc->LANE ...
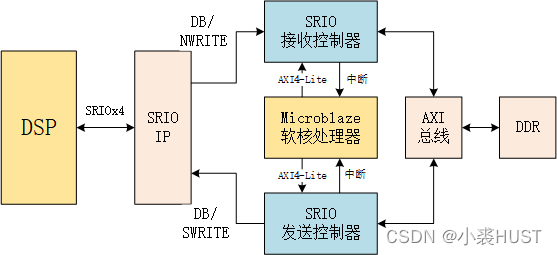
AXI Memory-Mapped SRIO收发控制器
Xilinx的SRIO IP可以用混合的接口或者分Initiator和Target的AXI4-Stream接口,数据是以Hello Format的包格式传输(SRIO IP的文档里有说明)。为了实现SRIO接口直接访问DDR数据空间,需要将Hello Format包格式转换为AXI4 master接口。
在我们的系统中,DSP和FPGA通过x4的SRIO链路互连,单条链路最高支持3.125Gbps。为了实现高效的数据传输,一般采用写的方式,比如NWRTIE包或者SWRITE包。如果用读的方式,就需要先发读请求包,然后过一段时间才能收到响应的数据,虽然可以连续发起多个读请求,但是面对大批量的数据传输,读的过程相对来说就比较繁琐,所以在我们的系统里主要用写的方式来实现数据传输。从DSP到FPGA的数据,由DSP发写数据包;从FPGA到DSP的数据,由FPGA发写数据包。
我们的DSP的SRIO外设支持DMA操作,可以将批量的数据以NWRITE包的形式发送。因此FPGA端的SRIO接收控制器主要负责解析NWRITE包;FPGA发送数据则可以采用SWRTIE包,它的额外开销最小, ...
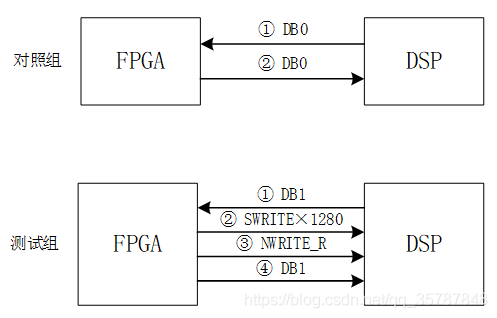
基于SRIO的FPGA与DSP间高速数据传输
引言
前段时间实现了DSP与FPGA之间的门铃通信,但SRIO不只是可以用来传门铃事务产生中断,它最大的优势在于能够实现嵌入式平台上的高速数据传输。我计划采用SWRITE事务包,从FPGA向DSP发送640×512×8bit图像数据,测试DSP端完成数据接收所需的时间。
参考资料:
SPRU976E - TMS320C645x DSP Serial RapidIO (SRIO) User’s Guide
SPRU732J - TMS320C64x/C64x+ DSP CPU and Instruction Set Reference Guide
FPGA发送数据至DSP
DSP端中断的产生在SPRU976E中有详细的说明,4.2节中指出,DSP在接收从外部送来的数据时,不管是Message还是Direct I/O的事务,外部的设备都需要通过门铃中断来告知DSP已经有数据传输完成。但是门铃事务和传数据的事务是独立的。如果发送端在发完数据后紧接着发门铃中断,有可能数据还未传输完成,DSP就已经开始响应门铃中断了。
为了避免这种情况的发生,发送端需要最后发送一个与前面发送的事 ...
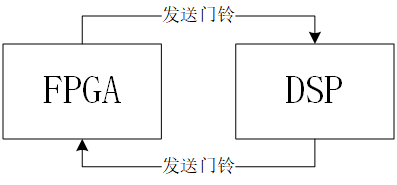
DSP与FPGA的SRIO通信实现
本文主要介绍在FPGA和DSP之间实现SRIO通信的过程。FPGA和DSP的型号分别为JFM7VX690T80-AS(XC7VX690T)和TMS320C6455。目前实现的是两者互相交替发送门铃事务,系统功能示意图如下图:
参考资料:
SPRAA89A - TMS320C6455 Design Guide and Comparisons to TMS320TC6416T
DS183 - Virtex‐7 T and XT FPGAs Data Sheet:DC and AC Switching Characteristics
ANTC206 - Differential Clock Translation
PG007 - Serial RapidIO Gen2 Endpoint v4.1 LogiCORE IP Product Guide
SPRU976E - TMS320C645x DSP Serial RapidIO (SRIO)
硬件连接
链路之间的连接采用100nF电容耦合,主要是不同的器件需要的时钟类型可能不同,需要注意。TMS320C6455需要采用LVDS ...
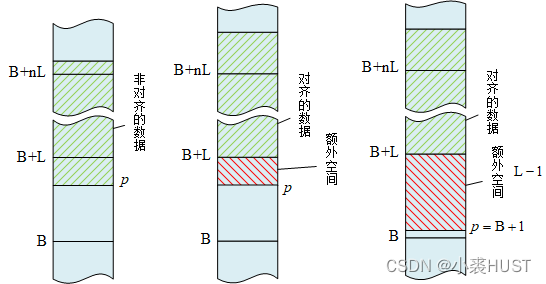
分配对齐的内存空间
最近用了别人写的一个FFT硬件加速模块,要求DDR中的数据对齐4k边界,估计这个模块用的数据总线是AXI协议的,AXI的突发传输不能超过4k边界。所用的平台是C6678DSP,编译器支持的C++版本是C++98,没有aligned new,所以只能自己写aligned_malloc函数。
额外空间开销
C++的new本质上调用的是malloc函数,malloc可以在堆区申请一定大小的空间,然后返回这段空间的首地址;与之对应的free函数可以释放已分配的堆区空间。
如上图所示,在调用malloc后返回指针ppp,B表示对齐的边界,对齐的字节数是L。一般来说我们得到的ppp指针指向的地址并不是对齐的。但我们可以多分配一点空间,使得数据存放到对齐的位置。那么这样做的话,最糟糕的情况下的额外开销就是L-1,此时ppp指针分配到了“边界+1”的位置处。
从分配的地址如何计算第一个对齐的地址。只需要在分配的地址上加上L-1,再把地址低位清零即可。比如要对齐4k边界:
addraligned=(p+0xFFF)&∼(0xFFF){ {addr_{aligned} = (p ...
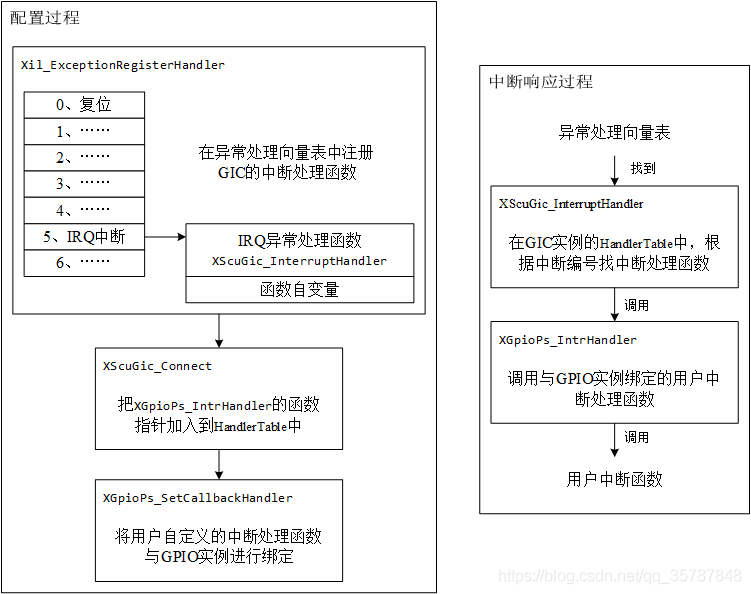
Zynq MIO中断配置实现与中断响应过程
中断结构
在进行中断相关的程序编写之前,首先需要了解zynq的中断框图。
这部分内容建议直接看xilinx官方手册ug585的第7章,里面有非常详细的介绍。xilinx文档可以直接用DocNav查看,会很方便。
从整体框图中可以看到,中断的来源主要分为三个部分,分别是软件中断、私有外设中断和共享外设中断。这里的顺序也是它中断ID编号的顺序,从前往后依次增大,总共有81个中断ID。
软件中断ID 0~15
私有外设中断ID 27 ~ 31,编号 16 ~ 26的ID是保留的
共享外设中断ID 32 ~ 91
这些中断源送进通用中断控制器(GIC)后再由GIC分配给两个CPU。手册中还有很多关于这三类中断的详细介绍。
有一个很好的地方是,共享外设中断虽然说是两个CPU共享的,但是只有其中一个CPU会进行处理,而不需要额外的加互斥锁之类的操作。
比较让我在意的是这里的共享外设中断除了那几个来自PL的中断可以自定义中断的触发类型,而其他的中断都是固定的触发类型。然而我们要用的GPIO中断可能会有不同的应用场景,这要是不能配置触发类型就很奇怪。后来发现这部分是在GP ...
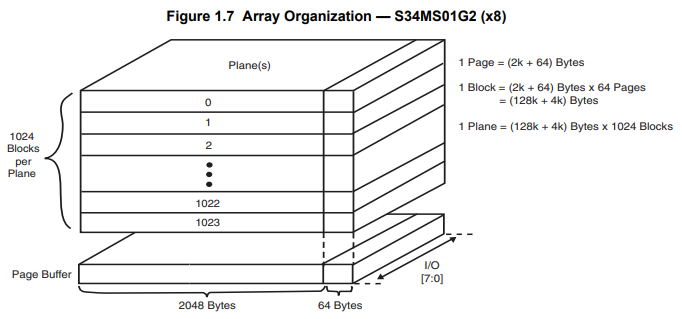
S34MS01G2 NAND Flash读写
NAND Flash 结构
直接拿人家数据手册里的图,Flash的存储结构分三个层次,从低到高依次是Page,Block和Plane。图中一个Page是2048个字节,然后旁边还有64个字节是用来存放校验信息的。64个Page组成一个Block,也就是图里的一层;1024层Block组合成一个Plane。
我用的主控是TI的C6678,它的EMIF支持NAND Flash读写,但是最多只支持512字节左右的ECC校验,而这个NAND Flash的一个Page已经超过了512字节,所以我在用的时候就没有ECC校验,虽然很有可能出问题,但是目前还没遇到。
接口
我用的这个NAND Flash只有一个8bit的接口。地址,数据,指令复用。需要按照要求的指令格式来完成读,写,擦除等操作。ALE和CLE引脚可以用来把8个IO的数据锁存到地址寄存器或者指令寄存器中。
读写Page
数据的读写是以Page为单位的,连续读一个Page里的内容的话,每次读一个数据,Flash内部的列地址(Col Addr)会自增,所以可以不需要额外的命令就能连续读一个Page的数据,就像一个FIFO一 ...