NAND Flash批量数据烧录
NAND Flash的读写之前已经写过一篇NAND Flash驱动相关的文章了,处理器用的是TI的8核DSP TMS320C6678,为了后续用它做大批量的数据处理,而现在有苦于暂时没有数据源,所以想先在Flash里存好待处理的数据,后面用起来方便一点。
为了准备尽可能多的数据,128MB容量的NAND Flash,我准备往里面写125MB。
一开始我特别激动,我就准备把这些数据写成常量,然后放到工程里一起编译,最后用仿真器下载进去。这一个数据文件就得几百兆。
后来试了一下发现,这文件太大了,CCS也扛不住,CCS还提示了“JVM heap low detected”,后来我还不死心,想办法提高CCS的heap size,但都没有很好的效果。125M数据确实有点多。
为了解决这个问题,我就想用串口吧。因为现在板子上6678能跟上位机直接通信的除了JTAG,也就只有串口了。但串口的速度又快不上去,虽然能够做,但是做出来还是让人哭笑不得。
最后我用了3M的波特率(USB转422用的FT232,最高只支持3M波特率),然后实际传输的过程中受到NAND Flash写入 ...
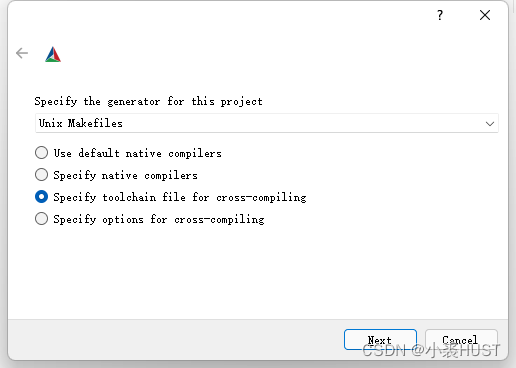
CMake构建CCS工程与EMCV编译
这两天折腾了一些不是那么有用的东西,用CMake构建CCS工程,以及编译EMCV Library(嵌入式计算机视觉库)。为什么说不是那么有用呢?因为虽然可以用CMake编译TI的CCS工程,但是调试还是离不开CCS。用CMake只是让程序编写的开发环境变得轻便了,可以在VS Code的界面下完成代码编写和编译,但最后Emulation还是得用CCS。另外,EMCV是OpenCV1.x移植到C6000 DSP上的计算机视觉库,一开始我没注意OpenCV的版本,原以为现有的软件算法能够比较方便地移植到DSP上,但是OpenCV1.x基本已经没有人用了,数据类型的定义和OpenCV3有较大的差别,所以我暂时还没有用上这个库,只是编译了一下。
CMake入门
CMake官网教程
CMake Tools for Visual Studio Code
我现在用的CMake是3.22.1版本,网上有很多CMake的教程,官网的教程挺好的,从建立工程,到添加库,package,install,export可以说把编译C/C++工程的方方面面都涉及了。但也正是因为它覆盖全面,所以它不可能方 ...
QS世界大学排名与学科排名数据获取
QS世界大学排名有两个官方的网站,一个是国际网站,另一个是国内网站,上面的数据应该都是一样的,只是一个是英文,一个是中文。
综合排名
qsChina,也就是国内网站上的QS排名数据获取相对比较方便,因为它可以选择每页显示所有数据,而国际网站上的那个则每页最多100条数据。虽然有这样的问题,但我最后还是选择国际网站上的数据,因为有些大学的中文翻译很奇怪。
我主要采用的还是selenium,这个虽然很慢,但是比较稳定。
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061#encoding=utf-8from selenium.webdriver import Edgefrom selenium.webdriver.common.by import Byimport timeimport xlsxwriterWorkbook = xlsxwriter.Workbook("QSRank2022.x ...
微信公众号文章信息获取
实现这一个功能主要用到了selenium、mitmproxy和wechatarticles,利用selenium可以实现脚本模拟浏览器访问,mitmproxy配合wechatarticles获取文章信息。
参考文章:
python爬取微信公众号文章(包含文章内容和图片)
记一次微信公众号爬虫的经历(微信文章阅读点赞的获取)
微信公众号文章全自动采集(使用mitmproxy抓包,然后用pywinauto实现自动点击)微信app_msg动态获取
selenium
selenium有一个官网,建议通过官网的教程入门。Getting Started主要有两步(我用的是python),一个是安装python的包,另一个就是还要下载浏览器的驱动文件,并且设置好环境变量。
mitmproxy
mitmproxy也有一个官网,在官网文档里的Getting Started里面写了,它默认监听本地的8080端口。有了这个代理,我们就可以获取网络传输中的数据包,要把它用起来就需要对代理进行设置。因为后面需要微信客户端的数据包收发进行监听,所以我直接对系统的代理进行了设置。
可以直接在wi ...
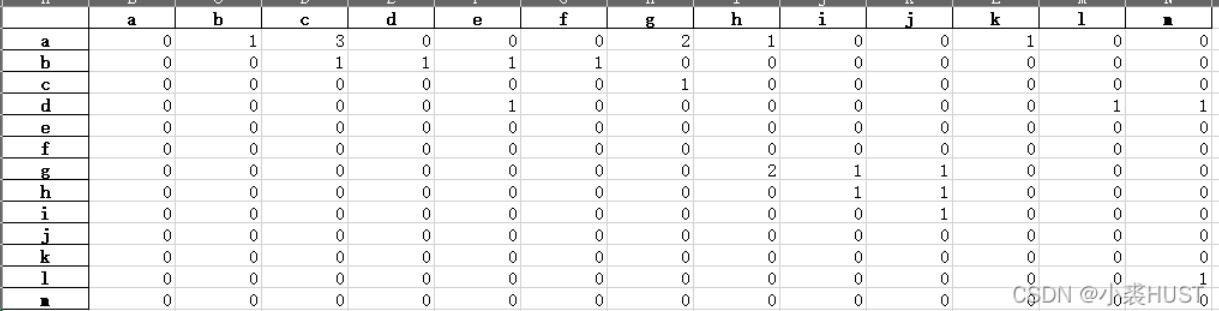
利用Pandas实现合作次数统计
最近有一个需求,就是我有一列数据,这列数据中的每一行表示完成某一项目的所有单位,我想统计这一列数据中,不同单位两两之间的合作次数。数据格式如下:
12345678910a;a;b;ca;c;b;d;eb;f;g;h;i;ja;g;ha;kd;l;ma;c;g
上面的每个字母都表示单位名称,不同单位之间用“;”隔开。实现功能的代码如下:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869# gen_matrix.pyimport pandas as pd# 将原始数据存在list.txt文件中,并且放在和这一脚本文件相同的目录下fp_list = open('list.txt',encoding='utf-8')# 初始化一个字典,用于存放所有矩阵数据,矩阵数据用“二维”字典存放matrix = {}# cnt计数用 ...
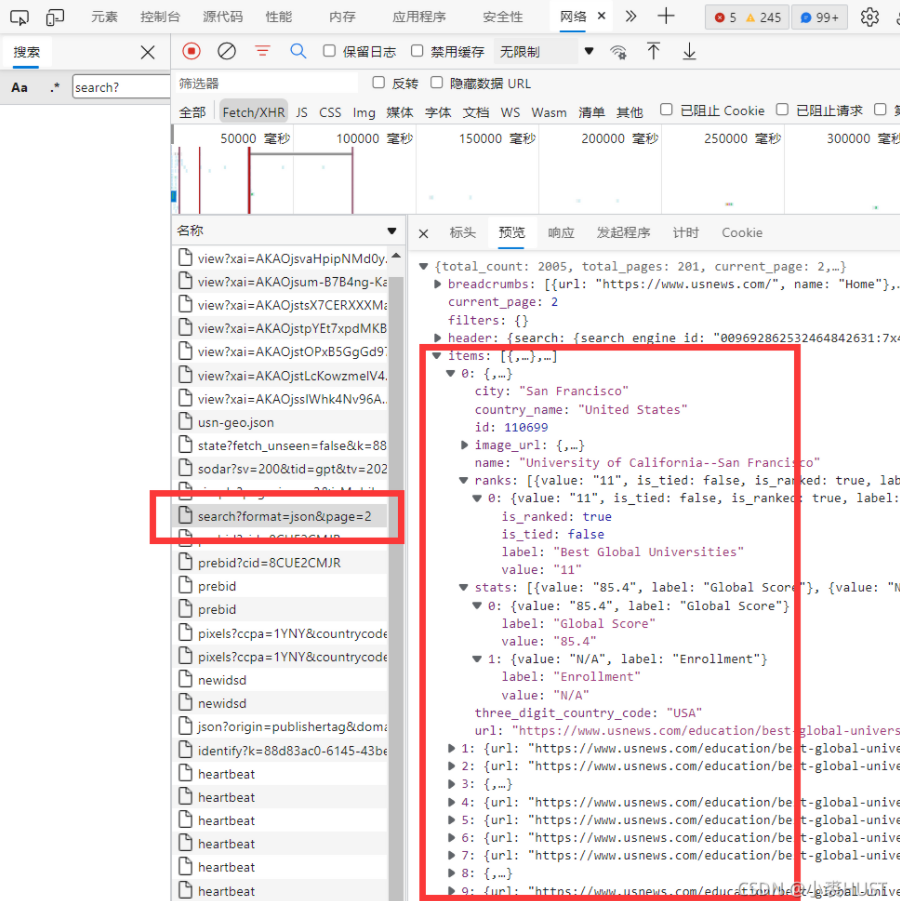
US News大学排名数据获取
US News的大学排名数据获取有一点点复杂。US News 2022 Best Global Universities Rankings网页是动态刷新的,数据量也比较大。数据获取总共分为三步:
flowchart LR
id1(获取大学基本信息)-->id2(获取每所大学的详细信息)-->id3(各学科各大学排名指标)
获取基本信息
在不断下拉的过程中打开F12调试工具,可以看到有一个“search?format=json&page=”开头的包,这个包的响应里面就有一些大学的基本信息。每个响应包里有10所大学的信息。
再看这个包的标头,就可以找到它的“请求URL”,我们也只要发这个请求URL,就可以获取相应的响应包。总共有2005所大学,所以只要循环201次即可。
1234567891011121314151617181920212223#encoding=utf-8import requestsimport timefp = open('collegeInfo.txt', 'w', en ...
THE、软科世界大学排名数据获取
THE大学排名
THE大学排名的数据比较容易获取,THE大学排名2022,所有数据都可以在这一个网页中找到。
“any subject”下拉菜单中可以选择不同学科,如果不选的话那就是综合排名;
不需要翻页,一页就是一个学科;
每种学科(包括综合排名)排名都可以写入一个excel中;
每种学科排名有两个标签栏中的数据需要获取,一个是“Rankings”,一个是“Scores”。
遇到的问题是,“any subject”的“select”是不可见的,所以不能用selemium的Select方法,解决方法就是用js脚本让它显示出来:
1234#get select object and make it visiblesel = Select(driver.find_element(By.XPATH, '//*[@id="subjects"]'))js = 'document.querySelectorAll("select")[3].style.display="block";' ...

ESI文章详细信息获取
每次ESI数据更新之后,有些文章是热点文章,有些文章是研究前沿,就如下图中的红框标示出来的一样。但这部分数据,主要是研究前沿的文章,在ESI导出的数据中看不到。所以需要想办法获取这部分数据。
获取数据
观察发现,每次翻页,都会有下面这样的一个请求包被发送,并获得json格式的数据,因此我们只要照着它的请求方式发送请求,就能获得相应的数据。
直接发请求是拿不到数据的,需要带上cookies。所以我用selenium模拟浏览器登录,然后获取cookies。在用requests发请求的时候,带上这个cookies就可以拿到json格式的数据。具体代码如下,需要输入自己的ESI帐号和密码。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899# esi_ar ...
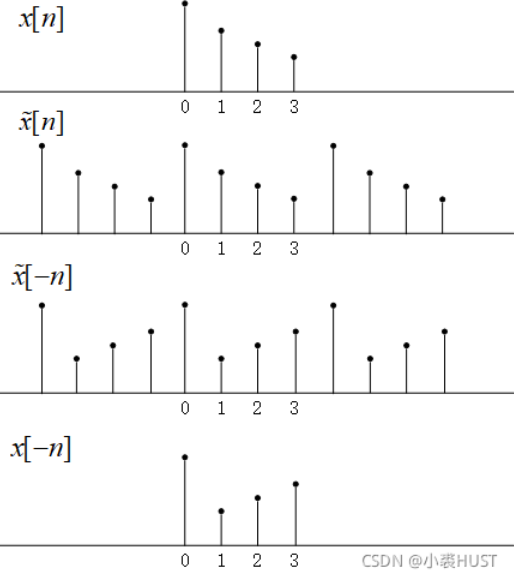
MOSSE算法推导
MOSSE是在Visual Object Tracking using Adaptive Correlation Filters这篇文章中提出来的,MOSSE的全称是Minimum Output Sum of Squared Error,令平方误差和最小来计算得到滤波器。
算法流程
相关滤波很容易理解,一帧图像经过相关运算(滤波器)之后得到的响应图中,响应最大的位置就是目标所在的位置。这个相关计算的模板也就是滤波器,它滤除了和它不相关的内容。
相关运算和卷积运算
相关Correlation和卷积Convolution有着紧密的联系。以一维的情况考虑。f[n]f[n]f[n]是原始序列,h[n]h[n]h[n]是滤波器,在它们都是实数的情况下,相关运算结果g[n]g[n]g[n]可以表示为:
g[n]=∑τ=−∞∞f[τ]h[n+τ]g[n] = \sum^{\infty}_{\tau=-\infty}f[\tau]h[n+\tau]
g[n]=τ=−∞∑∞f[τ]h[n+τ]
两者卷积的结果为:
f[n]∗h[n]=∑τ=−∞∞f[τ]h[τ−n]f[n]\ast ...
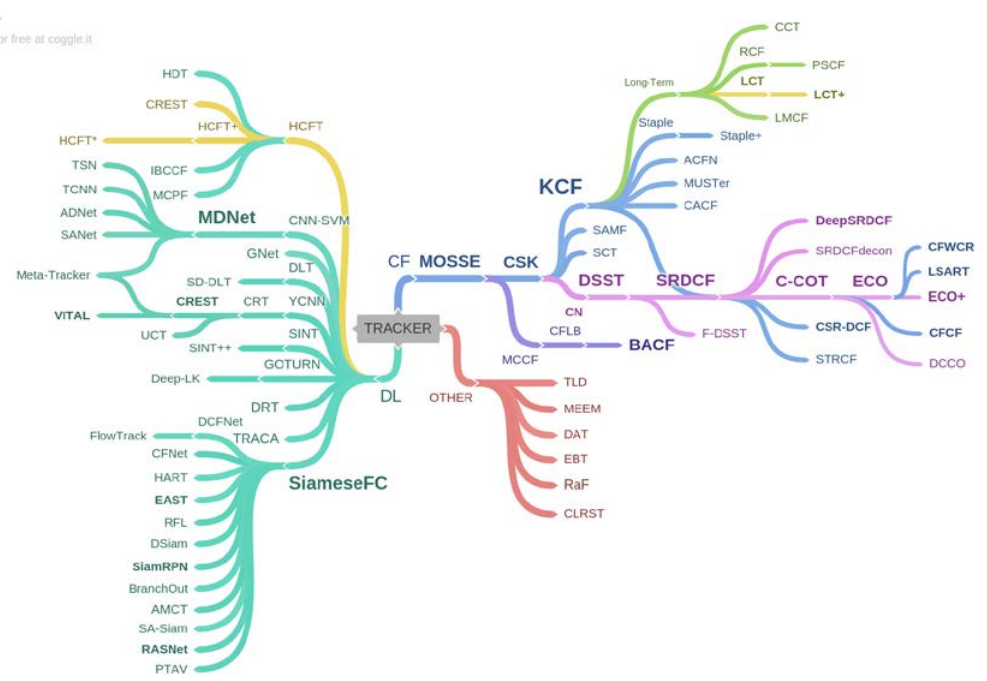
目标跟踪文章综述
引言
最近刚开始看论文,以前都是看数据手册,参考手册,User Guide, Application Note这类,就没好好看过论文。现在开始入门目标跟踪这一块,希望先熟悉一些算法,然后再去尝试嵌入式平台上的实现。
A Review of Visual Trackers and Analysis of its Application to Mobile Robot,2019年的一片目标跟踪相关的论文综述,大致介绍了目标跟踪算法的发展历程。
笔记
零碎的笔记
传统的目标跟踪算法,主要是用数学公式预测轨迹,而现在的目标跟踪算法则是把检测算法,跟踪策略,更新策略,在线分类等结合在一起,更加复杂。
文章中的表1给出了今年的一些数据集。表2给出了一些常用的特征。
目标跟踪的算法大致分为两种,不管是哪一种,特征提取非常重要!!一种是generative method,生成式方法,建立目标的模型后用模板匹配的方式找目标。另一种是判决式方法,discriminative method,它不生成模型,而是直接用神经网络判断是不是目标或者给出目标的概率。
跟踪的算法以前是用来解决检 ...